Tutorial#
This tutorial will walk you through the main features of atoti by creating an application to analyze the sales of a company.
We’ll see how to:
Load normalized data in multiple tables to create a multidimensional cube.
Define aggregated measures to provide application-specific and high-level insights.
Build no-code interactive charts and tables in JupyterLab.
Create dashboards in the built-in web app.
We encourage you to play this notebook in JupyterLab:
Copy the tutorial:
python -m atoti.copy_tutorial tutorialOpen JupyterLab:
jupyter labOpen the created tutorial directory and start playing its notebook.
For more information about a functionality, you can use the API reference or Shift ⇧ + Tab ⇥ on a Python symbol in JupyterLab.
Getting started#
From CSV to Cube#
In this part of the tutorial, you will create your first cube from a CSV file and learn multidimensional concepts such as cube, dimension, hierarchy, measure.
Let’s start by creating a session:
[1]:
import atoti as tt
session = tt.Session()
We can now load the data from a CSV file into an in-memory table called a table:
[2]:
sales_table = session.read_csv("data/sales.csv", keys=["Sale ID"])
We can have a look at the loaded data. They are sales from a company:
[3]:
sales_table.head()
[3]:
| Date | Shop | Product | Quantity | Unit price | |
|---|---|---|---|---|---|
| Sale ID | |||||
| S000000000 | 2021-02-04 | shop_0 | TAB_0 | 1.0 | 210.0 |
| S000000001 | 2021-02-03 | shop_1 | TAB_1 | 1.0 | 300.0 |
| S000000002 | 2021-02-02 | shop_2 | CHA_2 | 2.0 | 60.0 |
| S000000003 | 2021-02-01 | shop_3 | BED_3 | 1.0 | 150.0 |
| S000000004 | 2021-01-31 | shop_4 | BED_4 | 3.0 | 300.0 |
We will come back to tables in details later, for now we will use the one we have to create a cube:
[4]:
cube = session.create_cube(sales_table)
That’s it, you have created your first cube! But what’s a cube exactly and how to use it?
Multidimensional concepts#
A cube is a multidimensional view of some data, making it easy to explore, aggregate, filter and compare. It’s called a cube because each attribute of the data can be represented as a dimension of the cube:

The axes of the cube are called hierarchies. The purpose of multidimensional analysis is to visualize some numeric indicators at specific coordinates of the cube. These indicators are called measures. An example of measure would be the quantity of products sold.
We can list the hierarchies in our cube:
[5]:
# Aliasing the hierarchies property to a shorter variable name because we will use it a lot.
h = cube.hierarchies
h
[5]:
- Dimensions
- Sales
- Date
- Date
- Product
- Product
- Sale ID
- Sale ID
- Shop
- Shop
- Date
- Sales
The cube has automatically created a hierarchy for each non numeric column: Date, Product, Sale ID and Shop.
You can see that the hierarchy are grouped into dimensions. Here we have a single dimension called Sales, which is the name of the table the columns come from. We will see how to move hierarchies between dimensions later.
Hierarchies are also made of levels. Levels of the same hierarchy are attributes with a parent-child relationship. For instance, a city belongs to a country so Country and City could be the two levels of a Geography hierarchy.
At the moment, to keep it simple, we only have single-level hierarchies.
[6]:
l = cube.levels
Let’s have a look at the measures of the cube that have been inferred from the data:
[7]:
m = cube.measures
m
[7]:
- Measures
- Quantity.MEAN
- formatter: DOUBLE[#,###.00]
- Quantity.SUM
- formatter: DOUBLE[#,###.00]
- Unit price.MEAN
- formatter: DOUBLE[#,###.00]
- Unit price.SUM
- formatter: DOUBLE[#,###.00]
- contributors.COUNT
- formatter: INT[#,###]
- Quantity.MEAN
The cube has automatically created the sum and mean aggregations for all the numeric columns of the dataset.
Note that a measure isn’t a single result number, it’s more a formula that can be evaluated for any coordinates of the cube.
For instance, we can query the grand total of Quantity.SUM, which means summing the sold quantities over the whole dataset:

[8]:
cube.query(m["Quantity.SUM"])
[8]:
| Quantity.SUM | |
|---|---|
| 0 | 8,077.00 |
But we can also dice the cube to get the quantity for each Shop, which means taking one slice of the cube for each Shop:

[9]:
cube.query(m["Quantity.SUM"], levels=[l["Shop"]])
[9]:
| Quantity.SUM | |
|---|---|
| Shop | |
| shop_0 | 202.00 |
| shop_1 | 202.00 |
| shop_10 | 203.00 |
| shop_11 | 203.00 |
| shop_12 | 201.00 |
| shop_13 | 202.00 |
| shop_14 | 202.00 |
| shop_15 | 202.00 |
| shop_16 | 201.00 |
| shop_17 | 204.00 |
| shop_18 | 202.00 |
| shop_19 | 202.00 |
| shop_2 | 202.00 |
| shop_20 | 201.00 |
| shop_21 | 201.00 |
| shop_22 | 201.00 |
| shop_23 | 203.00 |
| shop_24 | 203.00 |
| shop_25 | 201.00 |
| shop_26 | 202.00 |
| shop_27 | 202.00 |
| shop_28 | 202.00 |
| shop_29 | 201.00 |
| shop_3 | 201.00 |
| shop_30 | 204.00 |
| shop_31 | 202.00 |
| shop_32 | 202.00 |
| shop_33 | 201.00 |
| shop_34 | 201.00 |
| shop_35 | 201.00 |
| shop_36 | 203.00 |
| shop_37 | 203.00 |
| shop_38 | 201.00 |
| shop_39 | 202.00 |
| shop_4 | 204.00 |
| shop_5 | 202.00 |
| shop_6 | 202.00 |
| shop_7 | 201.00 |
| shop_8 | 201.00 |
| shop_9 | 201.00 |
We can slice on a single Shop:

[10]:
cube.query(
m["Quantity.SUM"],
condition=l["Shop"] == "shop_0",
)
[10]:
| Quantity.SUM | |
|---|---|
| 0 | 202.00 |
We can dice along 2 different axes and take the quantity per product and date.

[11]:
cube.query(m["Quantity.SUM"], levels=[l["Date"], l["Product"]])
[11]:
| Quantity.SUM | ||
|---|---|---|
| Date | Product | |
| 2021-01-06 | BED_24 | 8.00 |
| BED_25 | 4.00 | |
| BED_26 | 6.00 | |
| BED_27 | 4.00 | |
| BED_3 | 2.00 | |
| ... | ... | ... |
| 2021-02-04 | TSH_52 | 6.00 |
| TSH_53 | 4.00 | |
| TSH_7 | 3.00 | |
| TSH_8 | 5.00 | |
| TSH_9 | 3.00 |
1830 rows × 1 columns
We can even combine these operations to slice on one hierarchy and dice on the two others:

[12]:
cube.query(
m["Quantity.SUM"],
levels=[l["Date"], l["Product"]],
condition=l["Shop"] == "shop_0",
)
[12]:
| Quantity.SUM | ||
|---|---|---|
| Date | Product | |
| 2021-01-15 | BED_24 | 1.00 |
| BED_26 | 1.00 | |
| BED_3 | 1.00 | |
| BED_4 | 1.00 | |
| BED_46 | 1.00 | |
| ... | ... | ... |
| 2021-02-04 | TSH_51 | 2.00 |
| TSH_52 | 1.00 | |
| TSH_53 | 1.00 | |
| TSH_7 | 1.00 | |
| TSH_9 | 1.00 |
125 rows × 1 columns
First visualization#
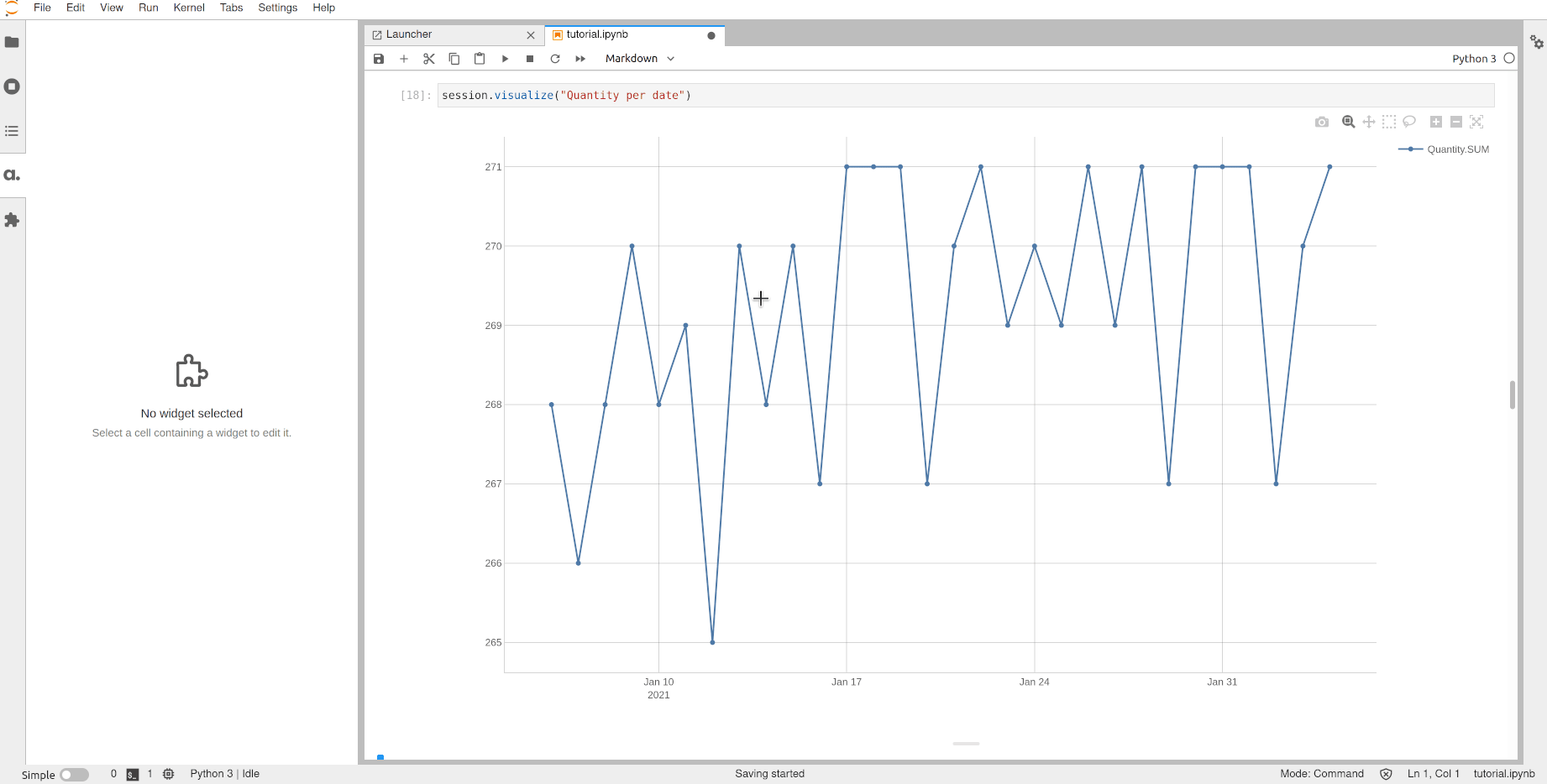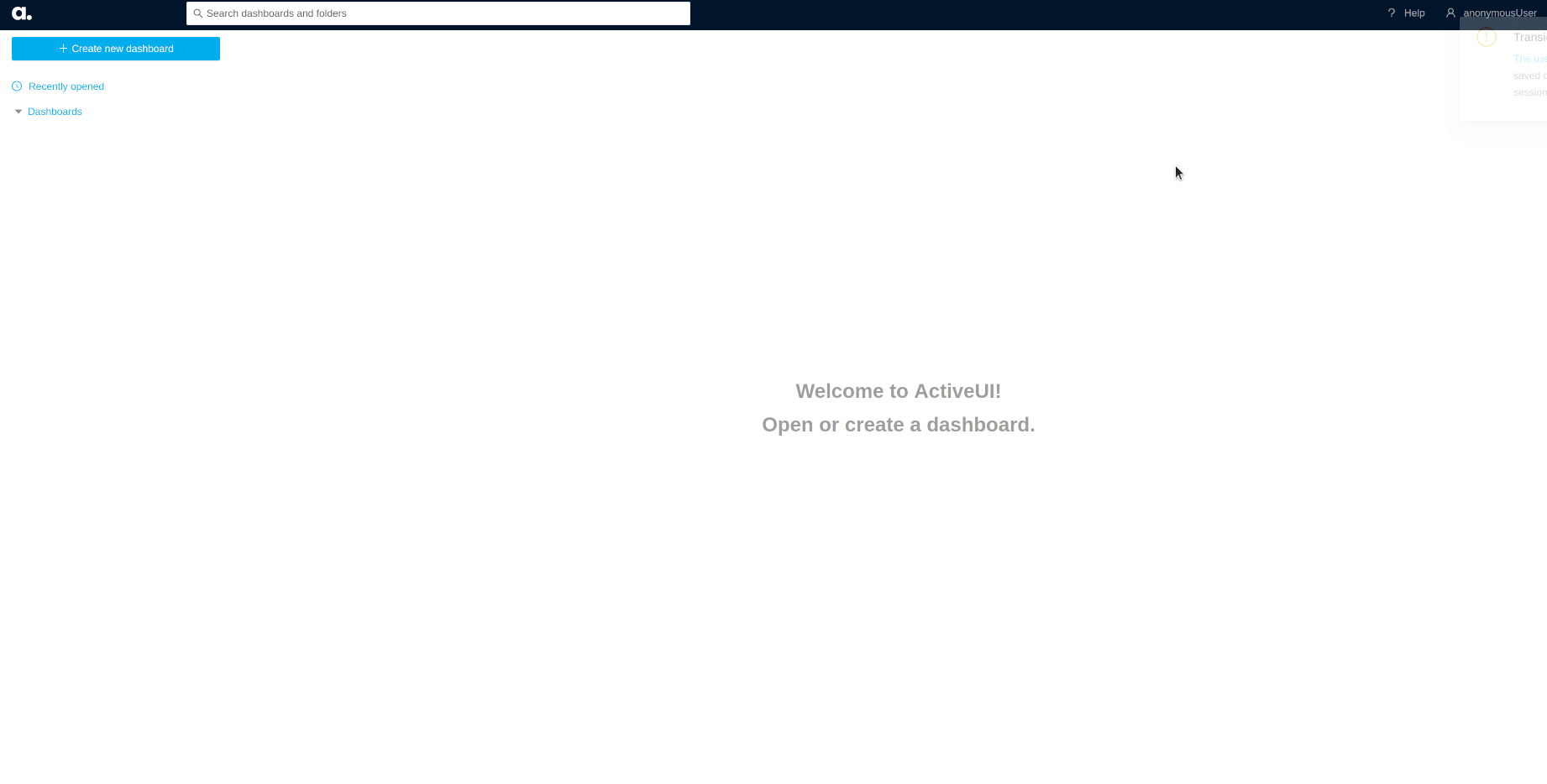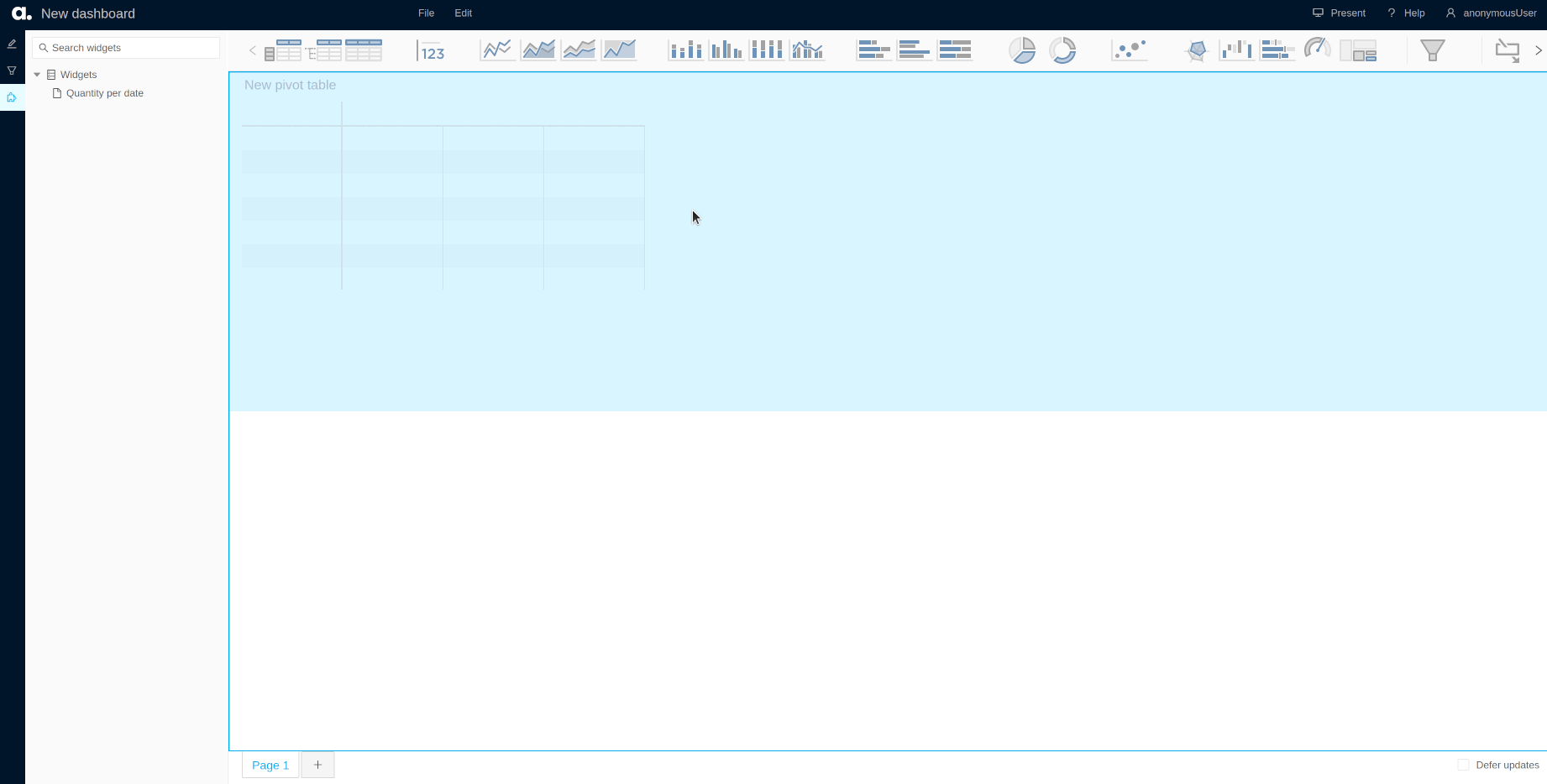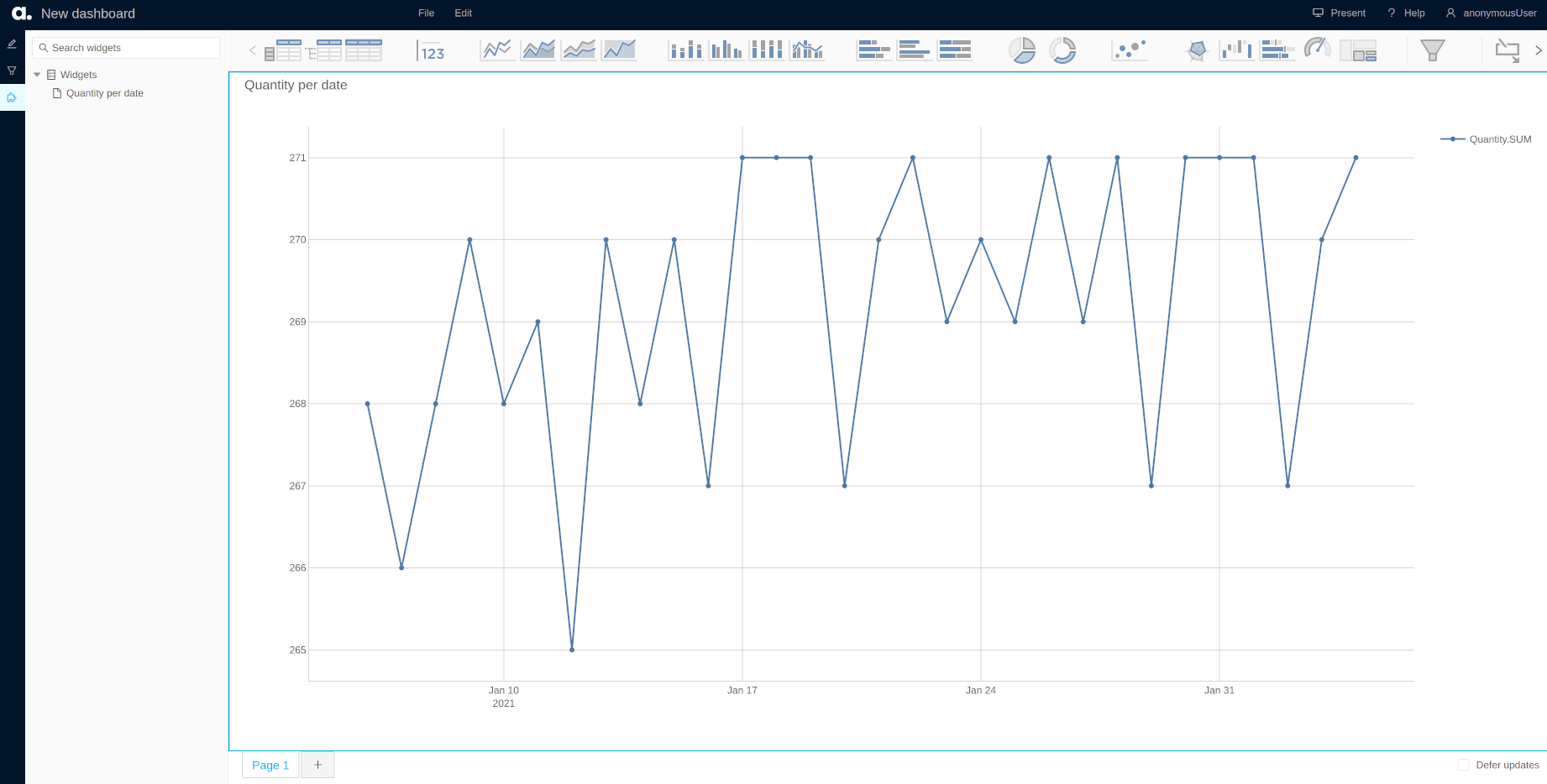
So far we have used cube.query() which returns a table as a pandas DataFrame but a better way to visualize multidimensional data is a pivot table. With atoti’s JupyterLab extension, you can do advanced and interactive visualizations such as pivot tables and charts directly into your notebook by calling session.visualize().
This will create a widget and open the atoti tab on the left with tools to manipulate the widget.
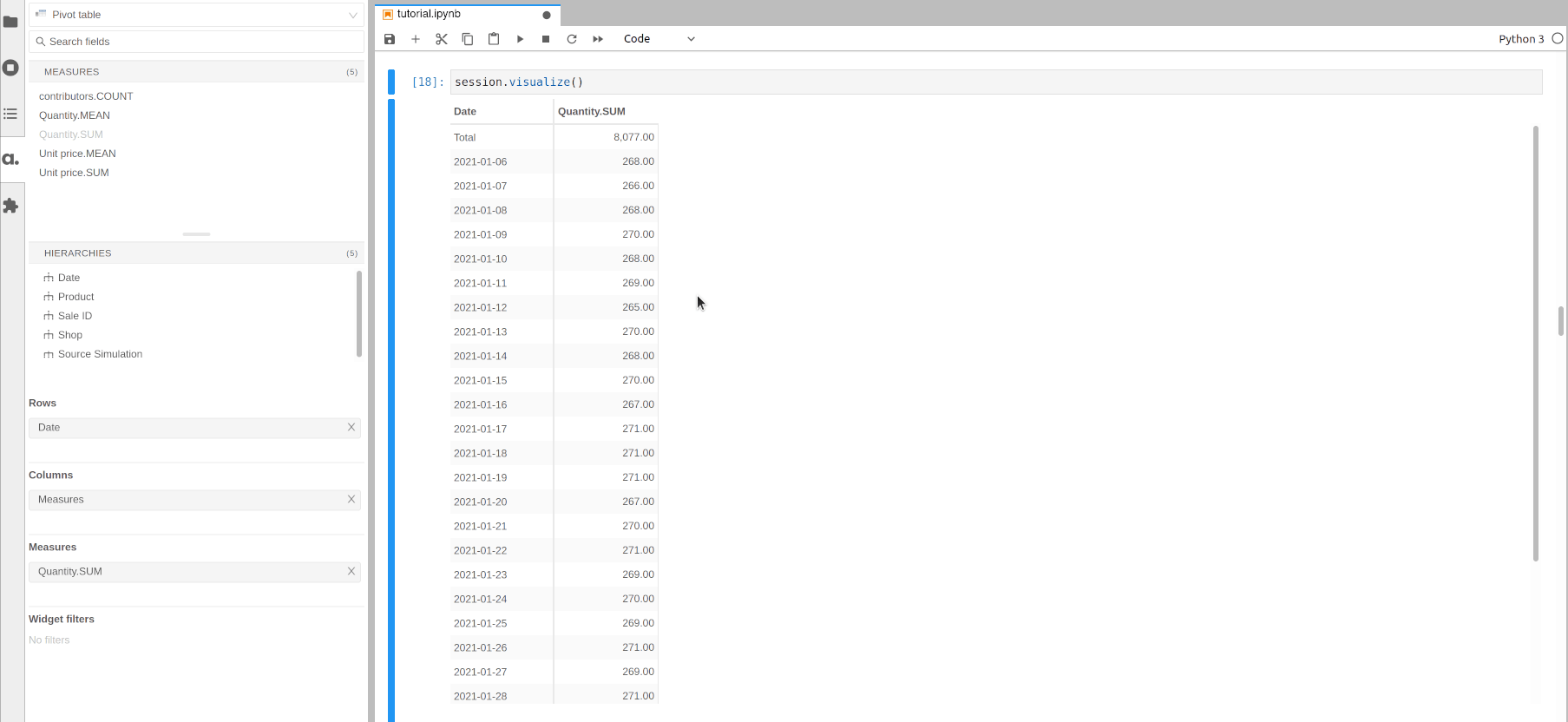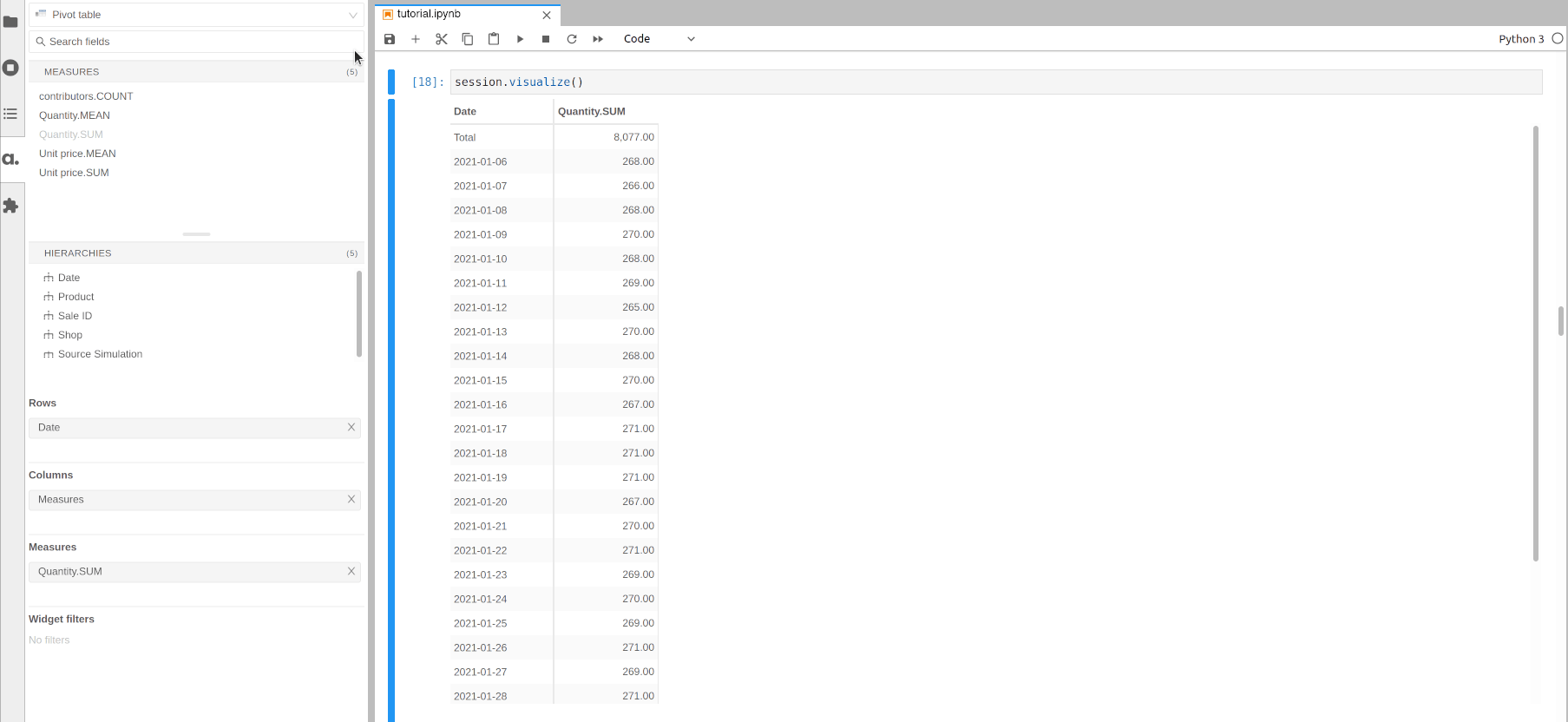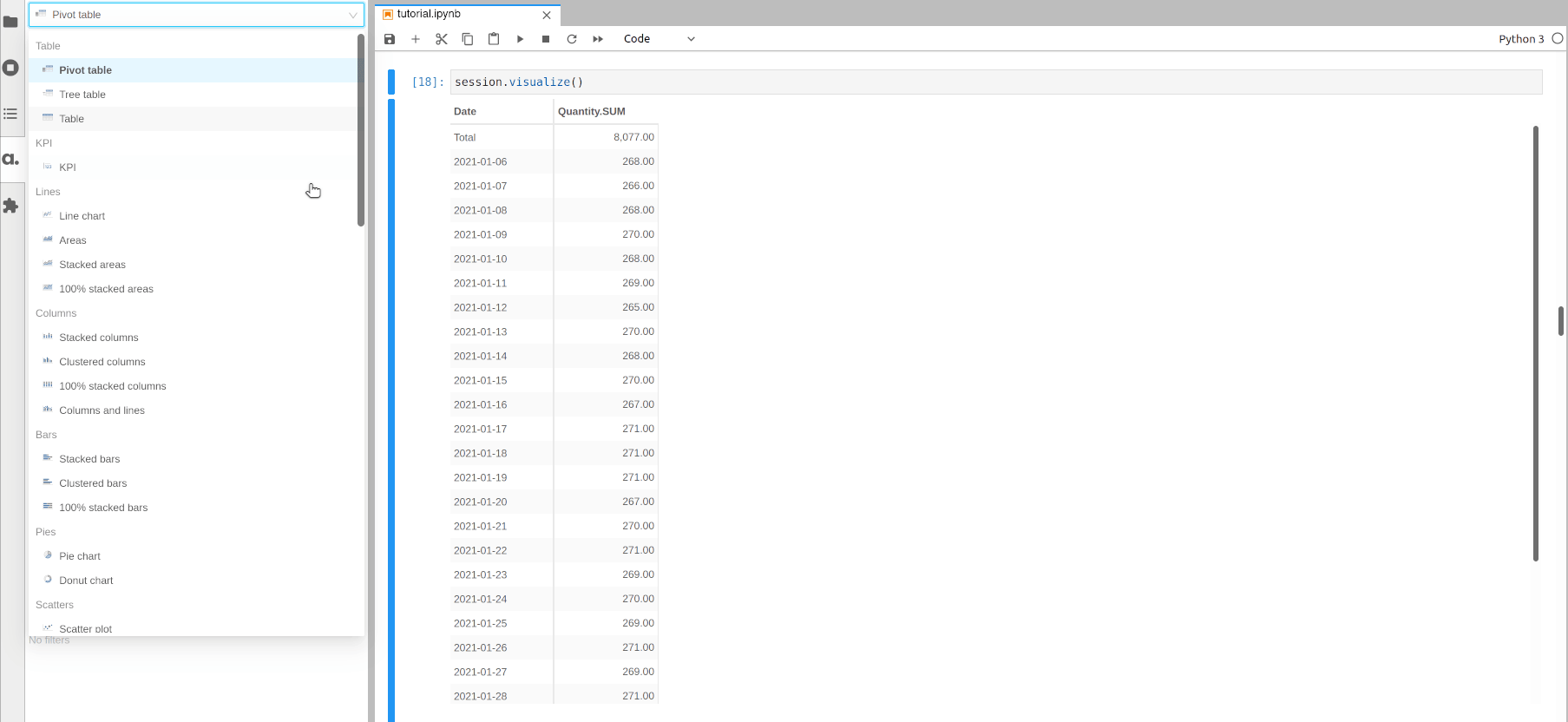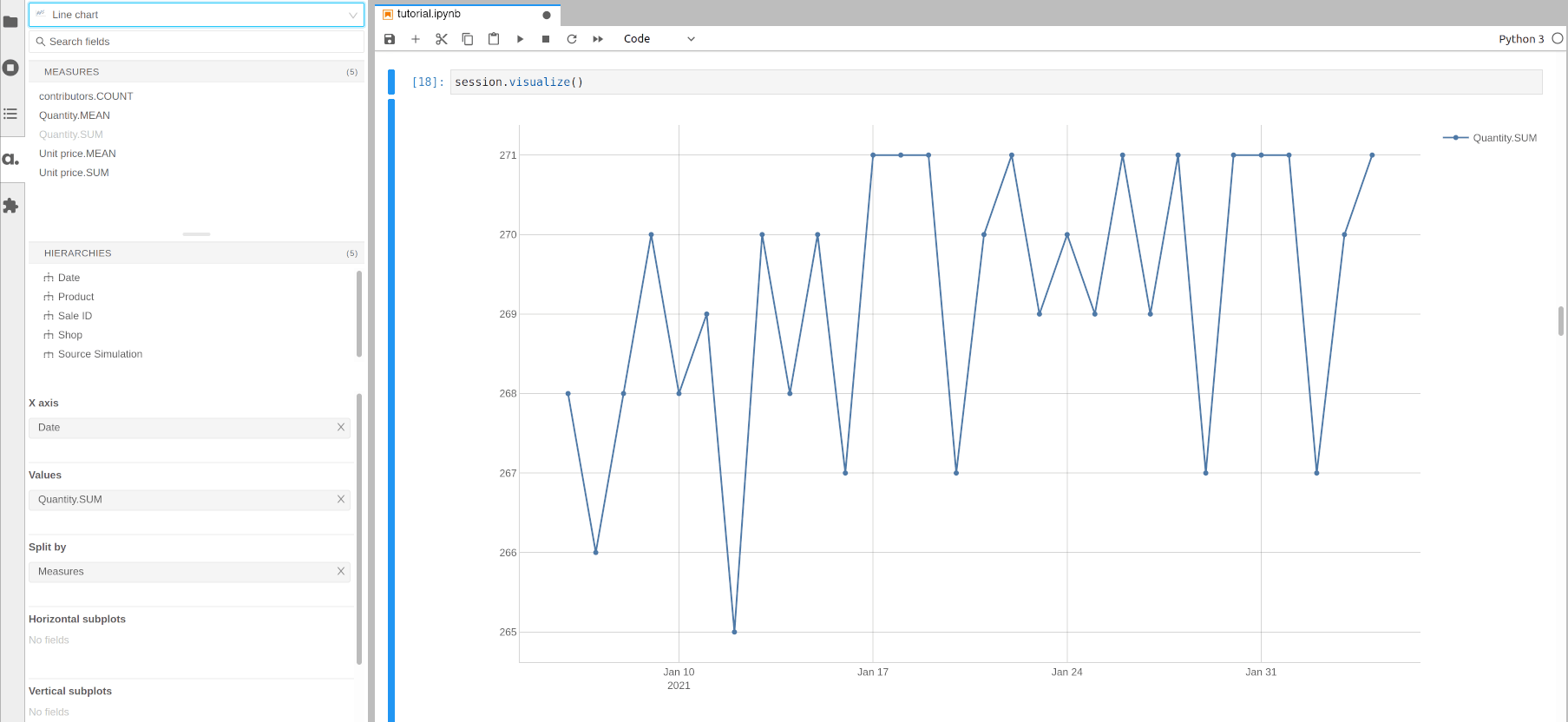
Let’s start by creating a pivot table:
Run
session.visualize().In the left panel, click on a measure such as Quantity.SUM to add it.
Click on a hierarchy such as Date to get the quantity per date.
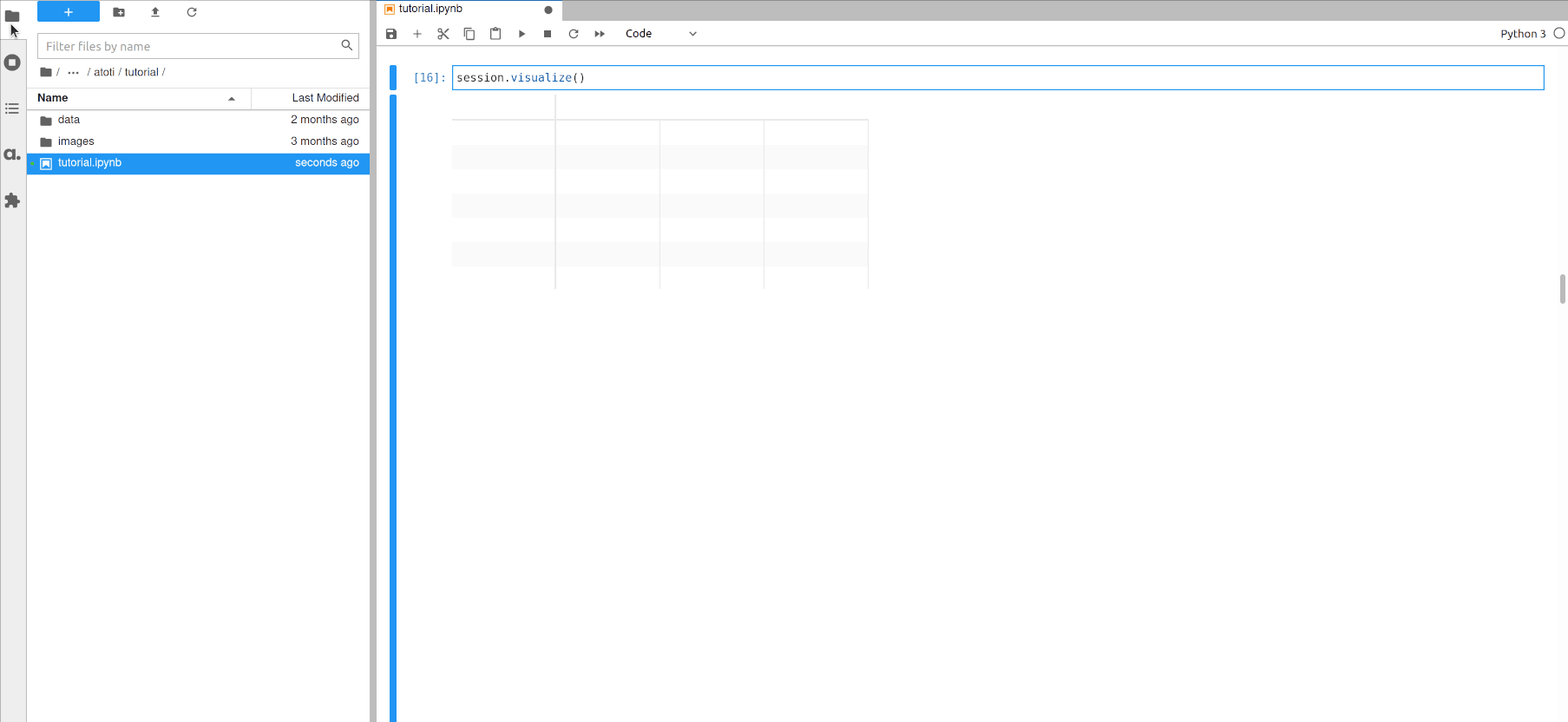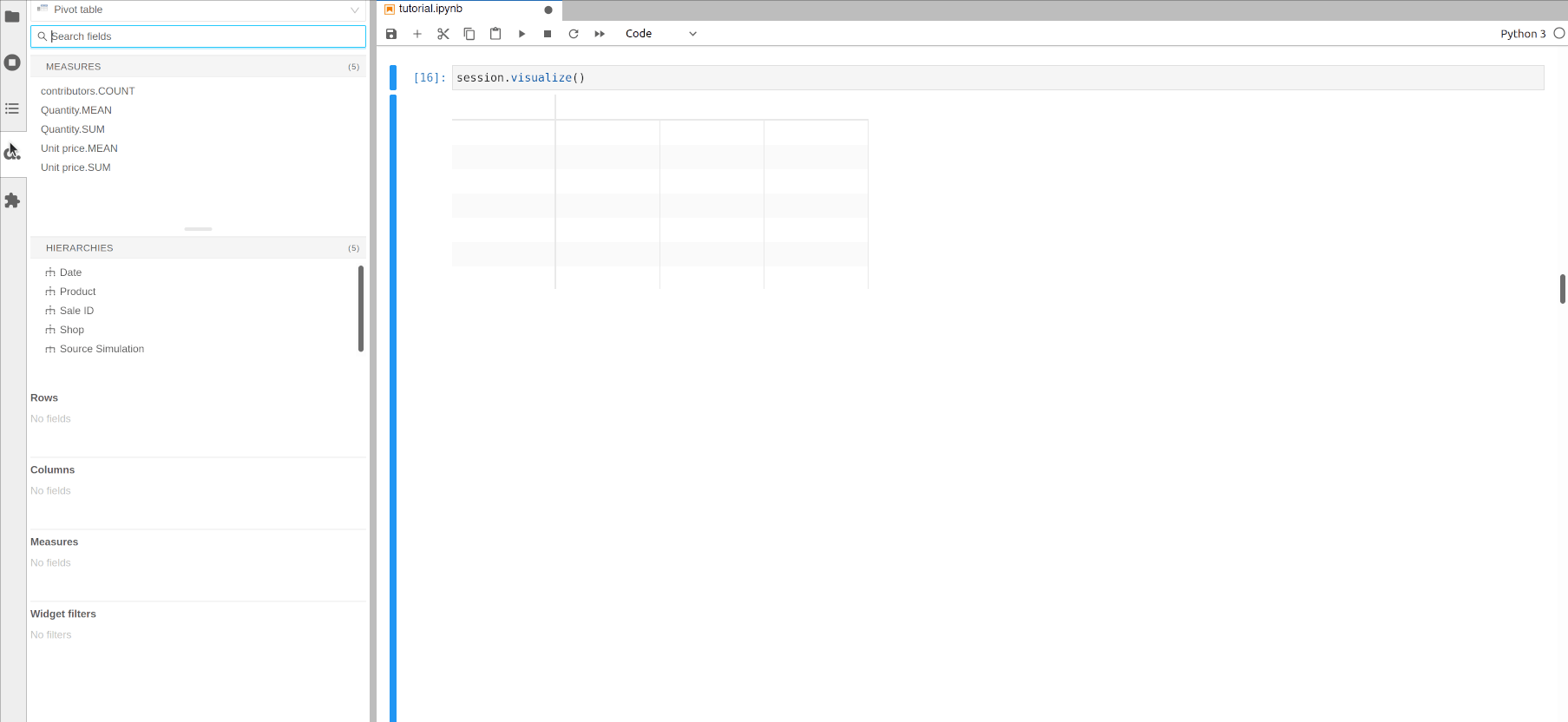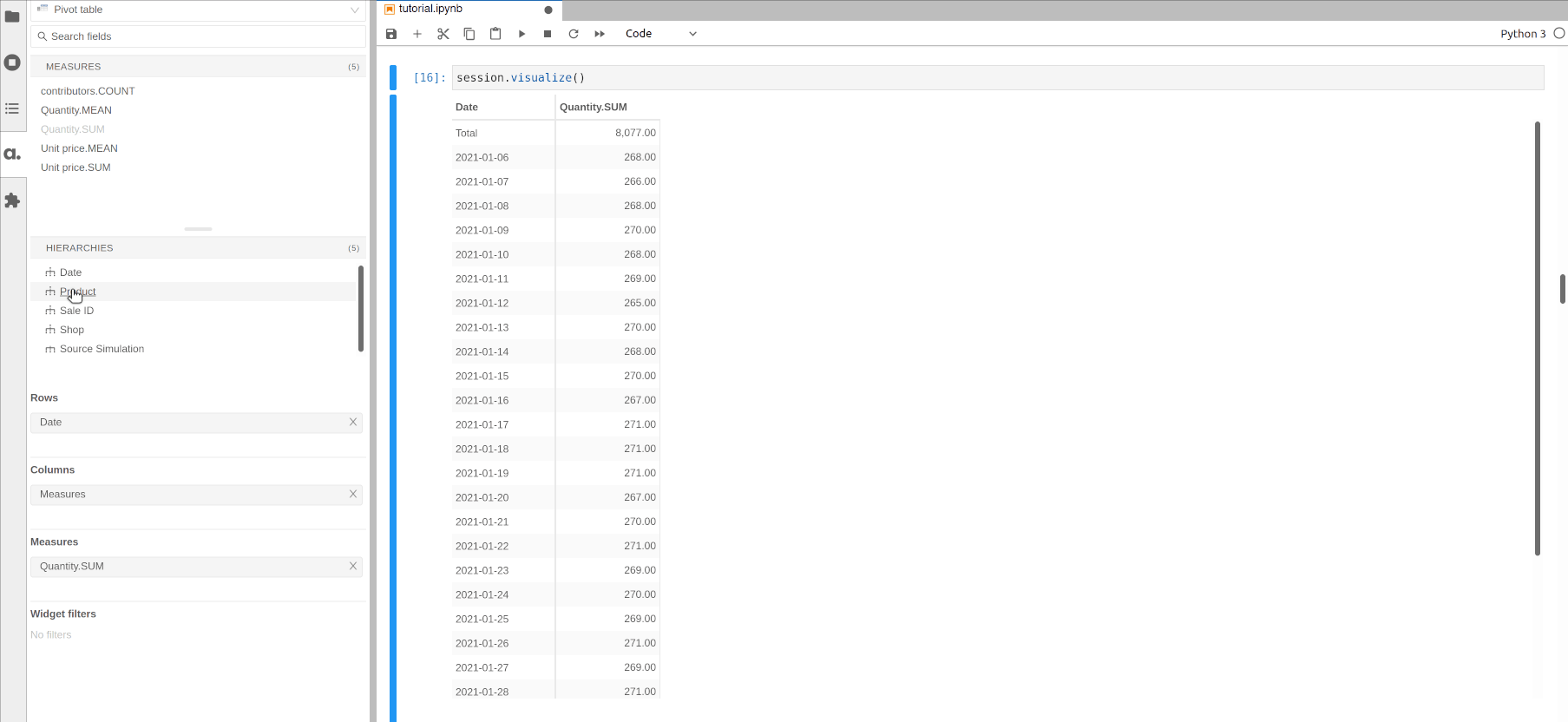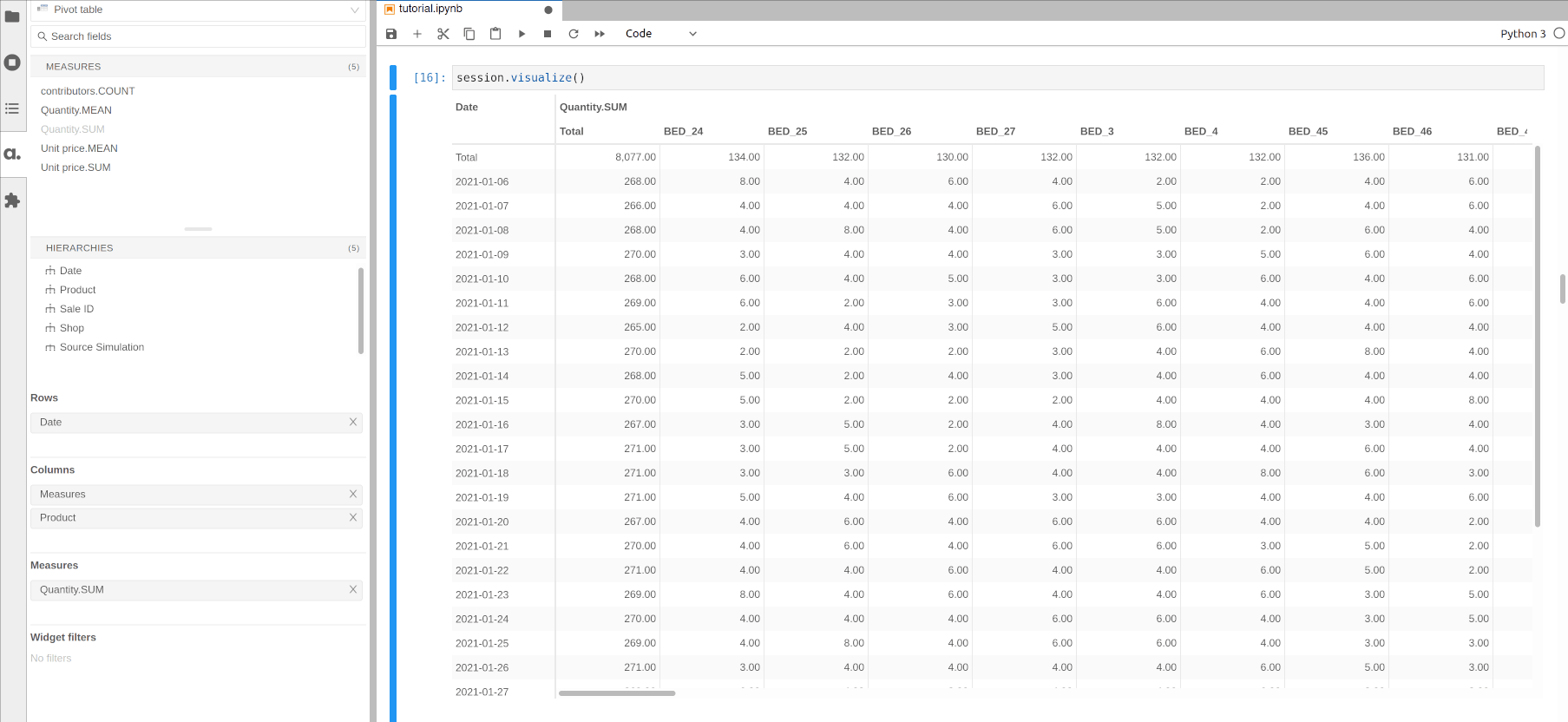
Drag and drop another hierarchy such as Product to the Columns section to get the quantity sold per day and per product.
[13]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
A pivot table can be switched to a chart.
For instance let’s switch to a simple line chart.
[14]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Drilldown and filters#
Multidimensional analysis is meant to be done from top to bottom: start by visualizing the indicators at the top level then drilldown to explain the top figures with more details.
For instance, we can visualize some measures per date then drilldown on Shop for a specific date, then see the products sold by a specific shop on this date.
Using the previous cube representation, this is like zooming more and more on a part of the cube.

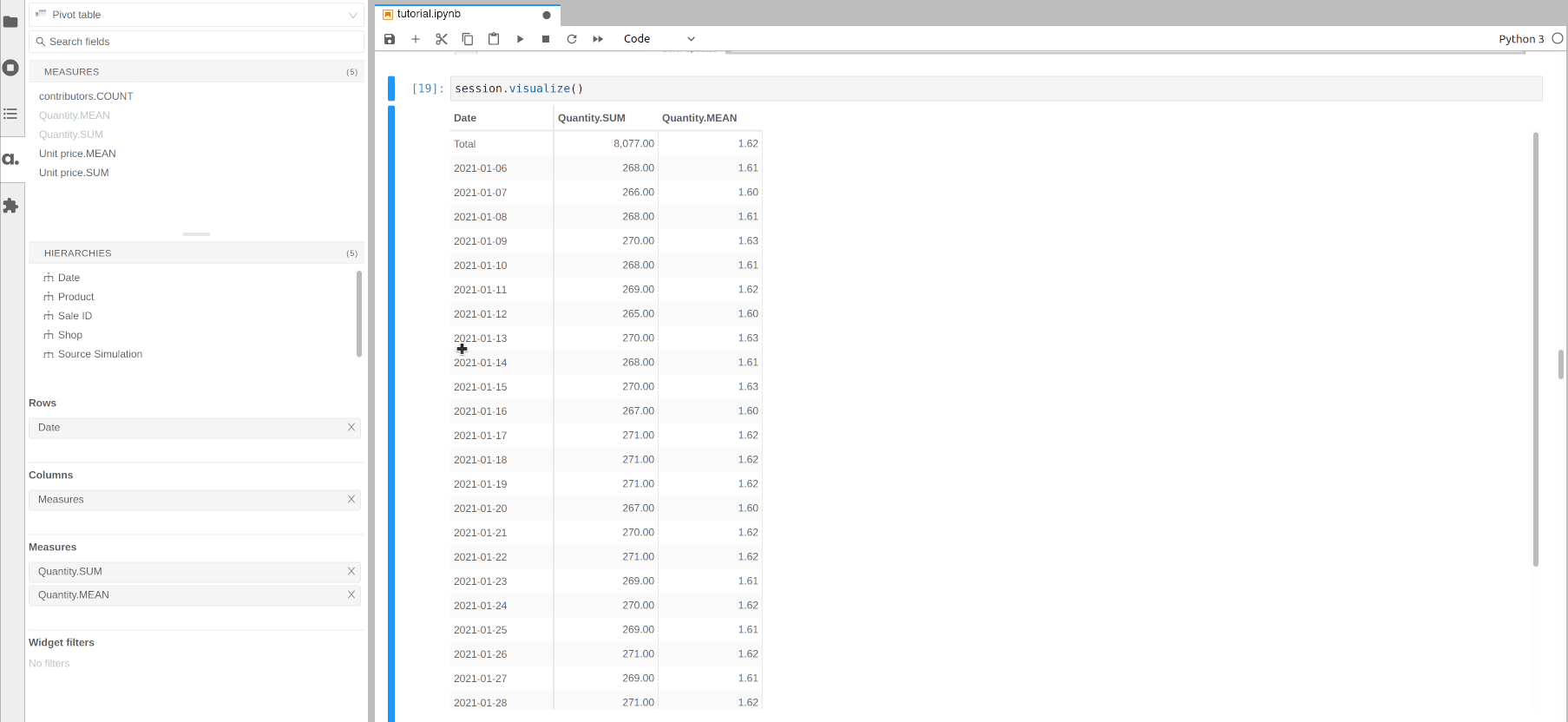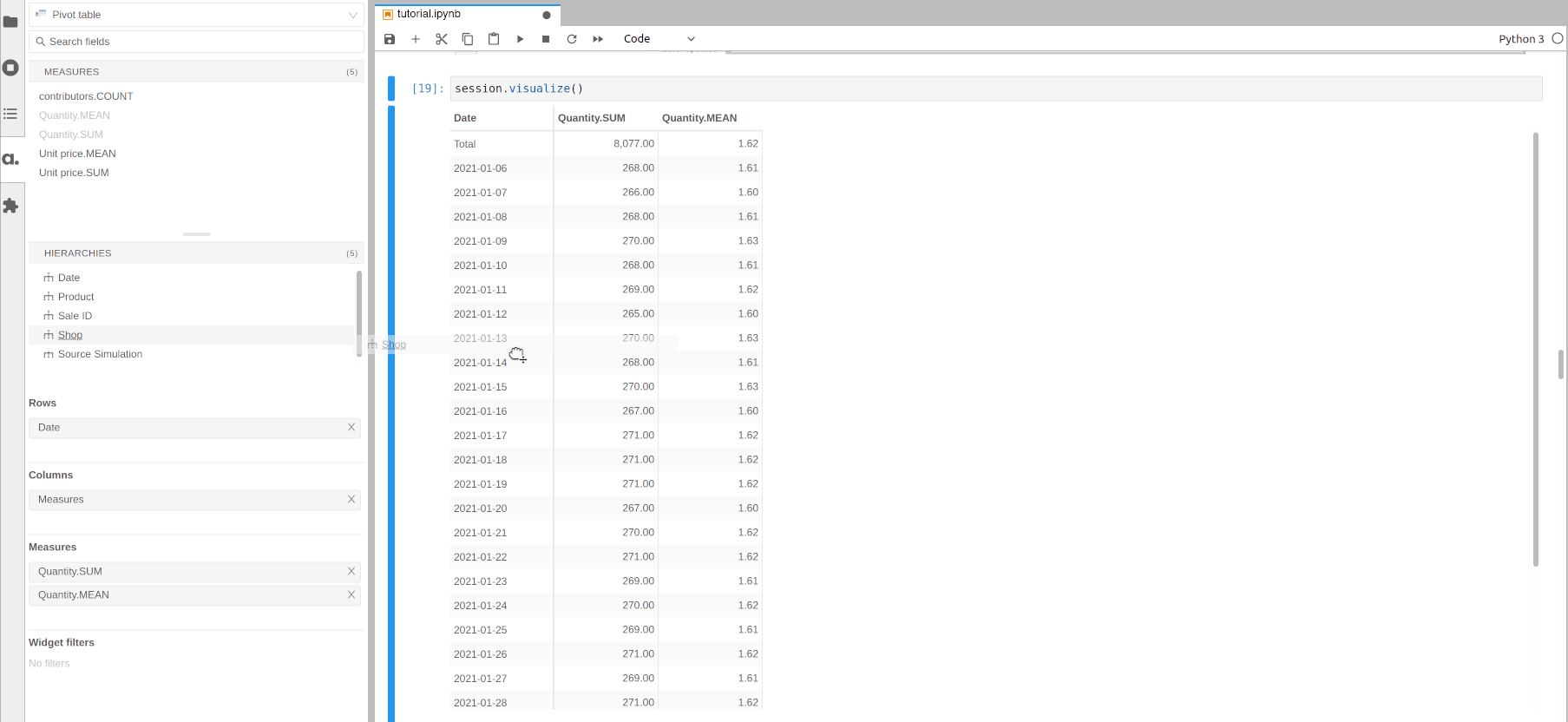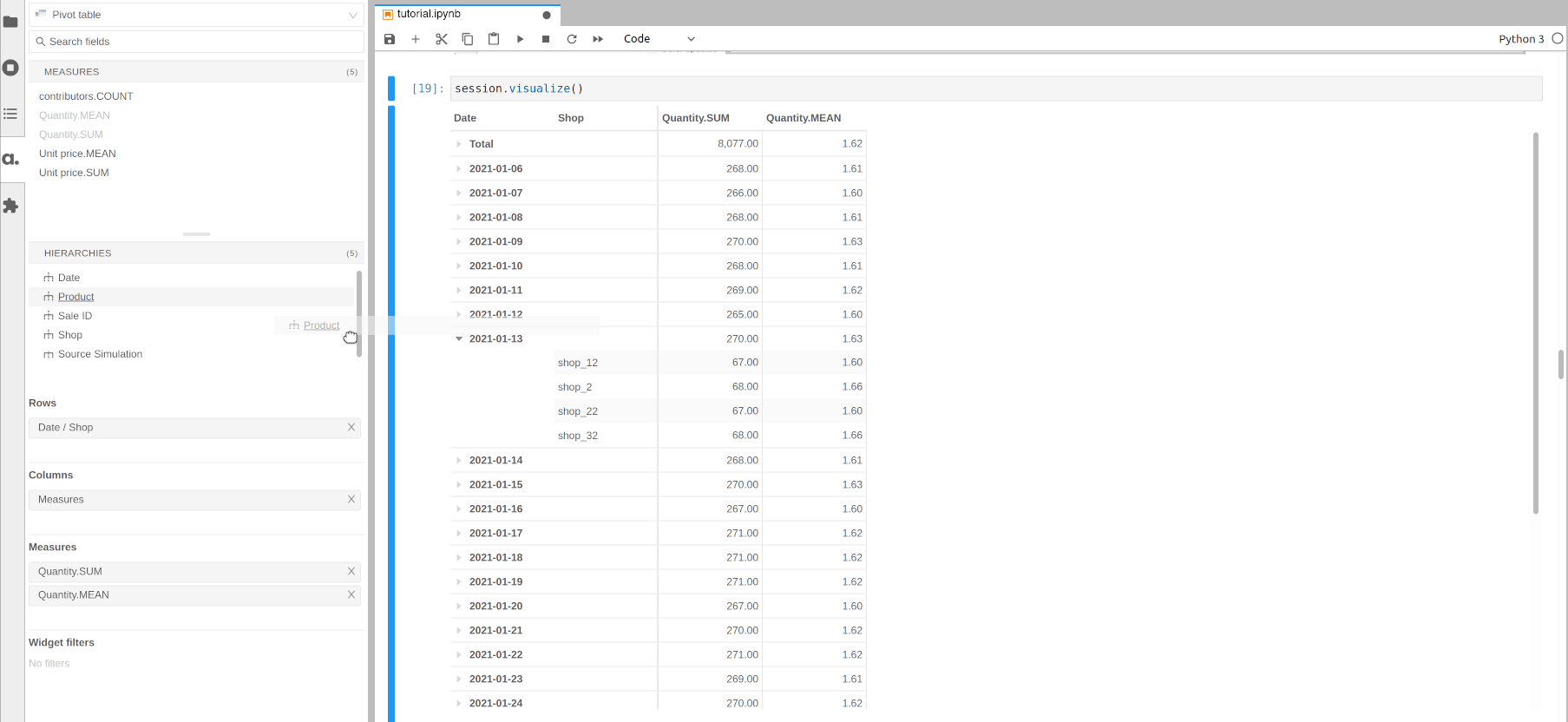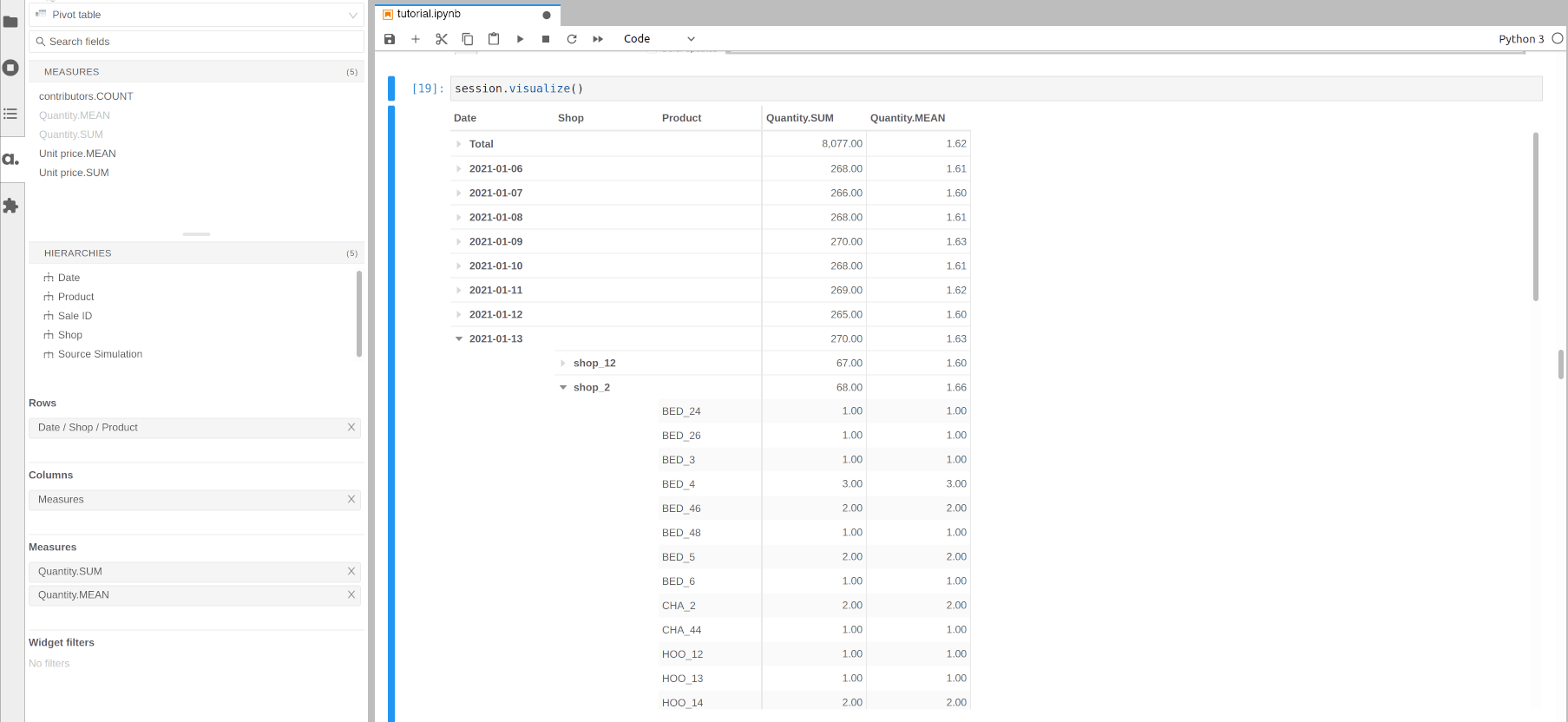
[15]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Hierarchies can be filtered when building widgets. Let’s apply a filter on the previous chart and only visualize the quantity for a group of selected products.
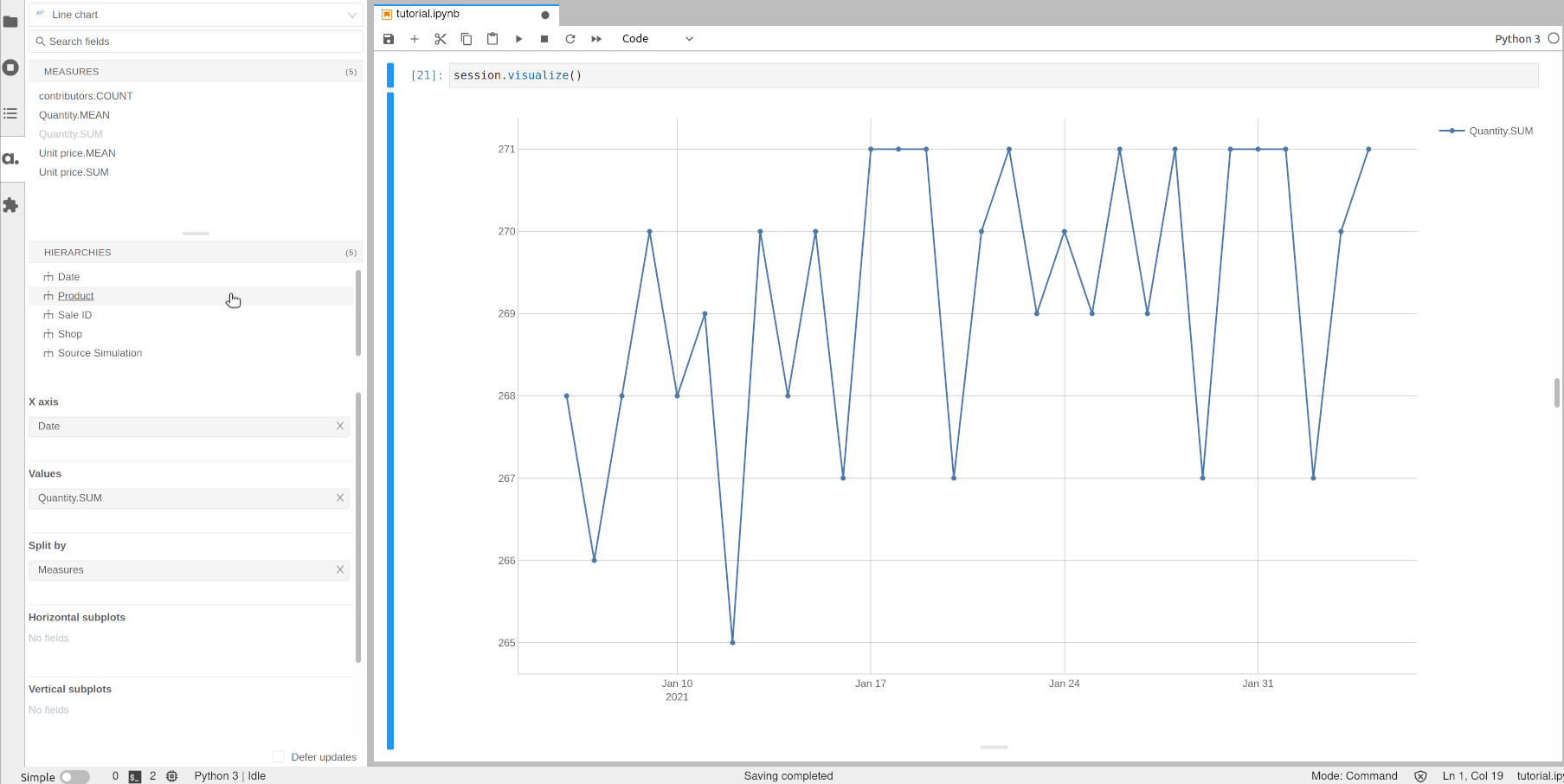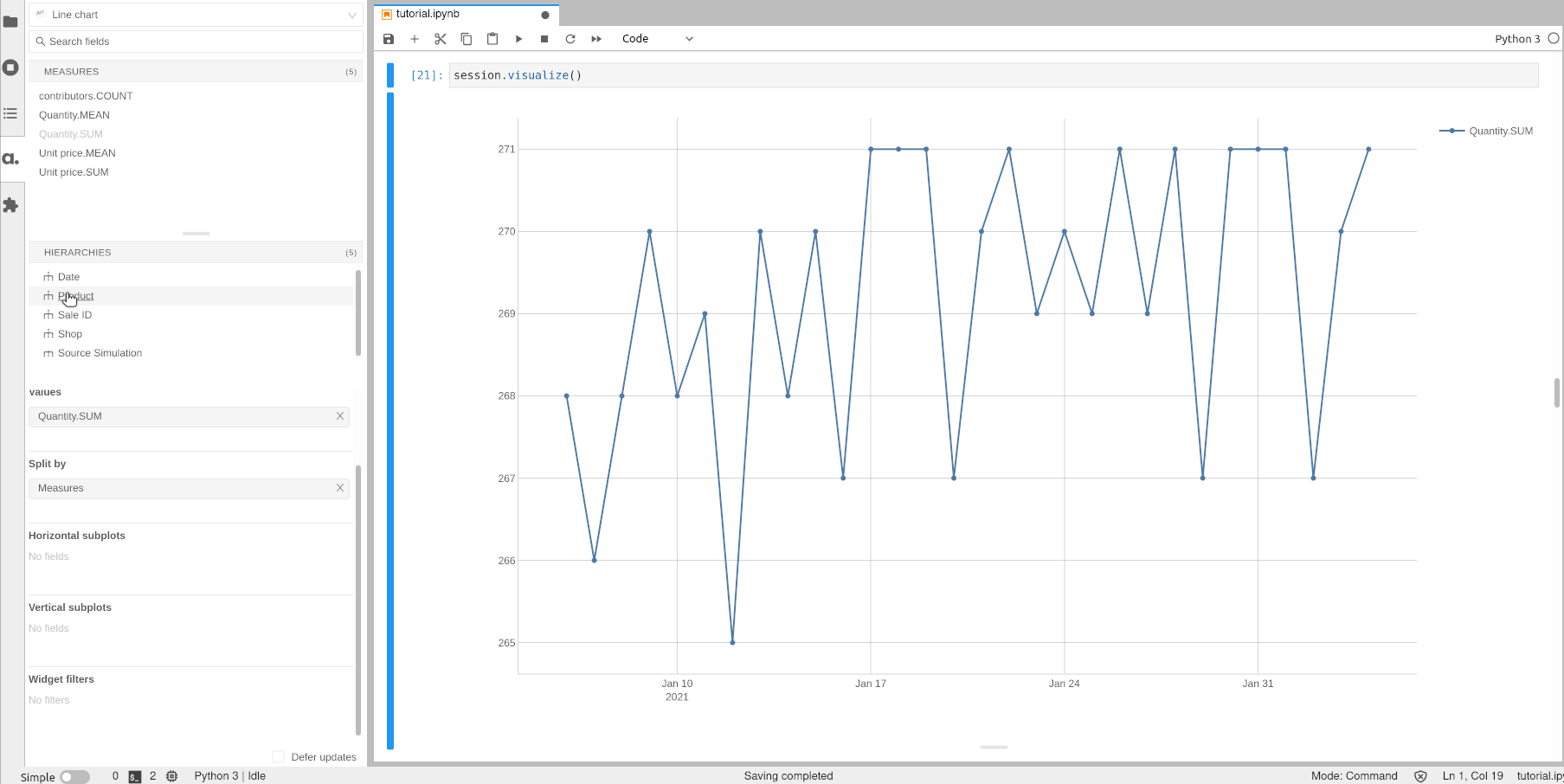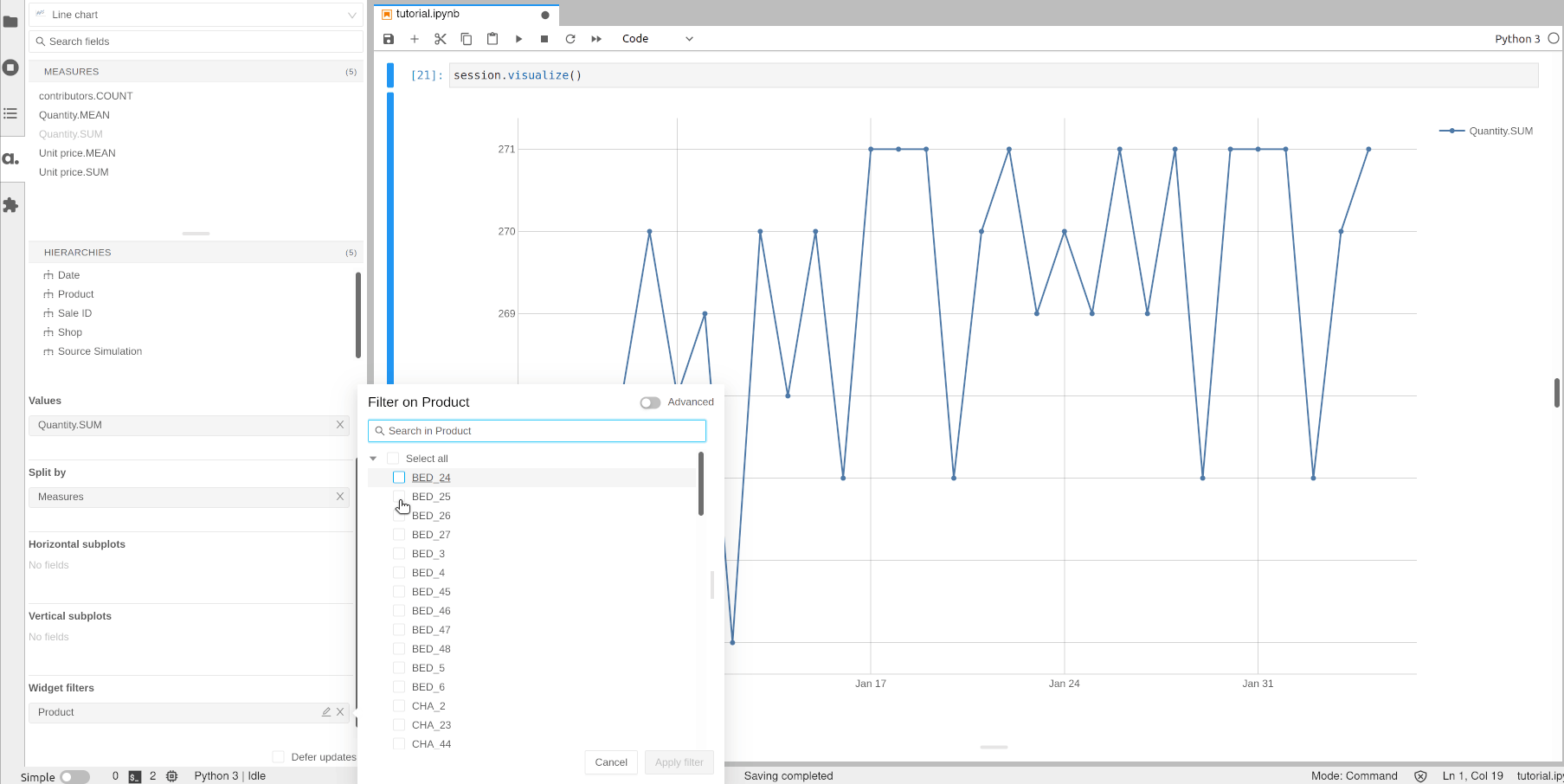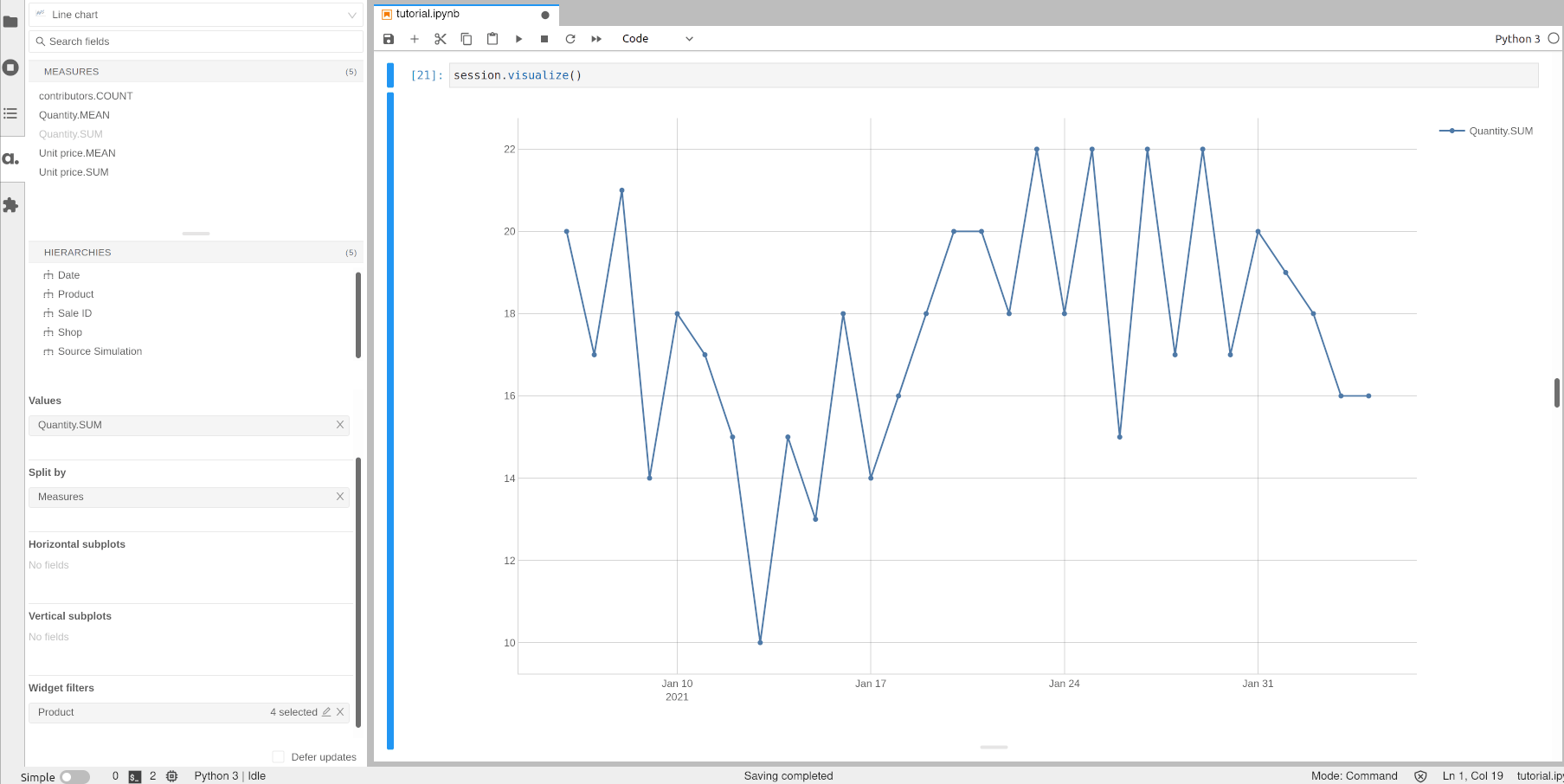
[16]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Dashboarding application#
Being able to quickly build widgets inside a notebook without coding is nice to rapidly explore the data, iterate on your model and share some results. However, to provide richer insights, dashboards are even better. That’s why atoti comes with a web application that can be accessed outside of the notebook and where widgets can be laid out to form dashboards.
The application can be accessed with this link:
[17]:
session.link()
[17]:
Open the notebook in JupyterLab with the atoti extension enabled to see this link.
It’s possible to publish widgets built in the notebook to the application by right clicking on them and selecting “Publish widget in app”. They will then be available in the “Saved widgets” section.
Enriching the cube#
In the previous section, you have learned how to create a basic cube and manipulate it. We will now enrich this cube with additional attributes and more interesting measures.
Join#
Currently, we have very limited information about our products: only the ID. We can load a CSV containing more details into a new table:
[18]:
products_table = session.read_csv("data/products.csv", keys=["Product"])
Note that a table can have a set of keys. These keys are the columns which make each line unique. Here, it’s the product ID.
If you try to insert a new row with the same keys as an existing row, it will override the existing one.
[19]:
products_table.head()
[19]:
| Category | Sub category | Size | Purchase price | Color | Brand | |
|---|---|---|---|---|---|---|
| Product | ||||||
| TAB_0 | Furniture | Table | 1m80 | 190.0 | black | Basic |
| TAB_1 | Furniture | Table | 2m40 | 280.0 | white | Mega |
| CHA_2 | Furniture | Chair | N/A | 48.0 | blue | Basic |
| BED_3 | Furniture | Bed | Single | 127.0 | red | Mega |
| BED_4 | Furniture | Bed | Double | 252.0 | brown | Basic |
This table contains the category, subcategory, size, color, purchase price and brand of the product. Both tables have a Product column we can use to join them.
Note that this is a database-like join and not a pandas-like join. All the details from products_table won’t be inlined into sales_table. Instead, this just declares a reference between these two tables that the cube can use to provide more analytical axes.
[20]:
sales_table.join(products_table, mapping={"Product": "Product"})
You can visualize the structure of the session’s tables:
[21]:
session.tables.schema
[21]:

The new columns have been automatically added to the cube as hierarchies, in a dimension with the same name as the new table:
[22]:
h
[22]:
- Dimensions
- Products
- Brand
- Brand
- Category
- Category
- Color
- Color
- Size
- Size
- Sub category
- Sub category
- Brand
- Sales
- Date
- Date
- Product
- Product
- Sale ID
- Sale ID
- Shop
- Shop
- Date
- Products
You can use them directly in a new widget. For instance, let’s create a bar chart to visualize the mean price per subcategory of product:
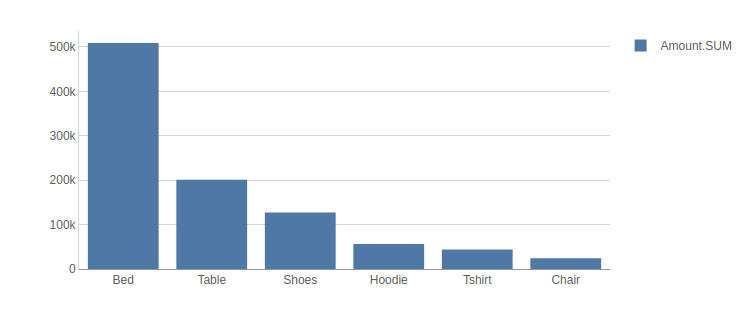
[23]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
We can also make a donut chart to see how all the sales are distributed between brands:
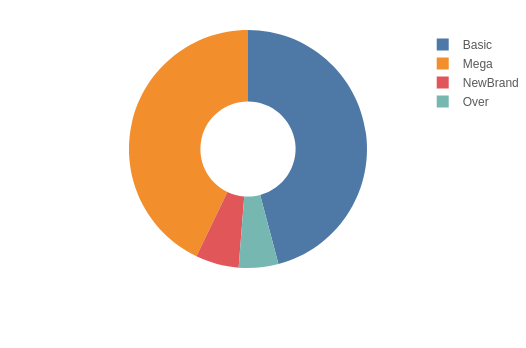
[24]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Note that after the join we can add a new measure called Purchase price.VALUE based on the corresponding column of the joined table. This measure represents the value of the column so it is only defined when all the keys of the joined table are expressed in the query.
[25]:
m["Purchase price.VALUE"] = tt.value(products_table["Purchase price"])
For instance we can check the purchase price per Product:
[26]:
cube.query(m["Purchase price.VALUE"], levels=[l["Product"]])
[26]:
| Purchase price.VALUE | |
|---|---|
| Product | |
| BED_24 | 127.00 |
| BED_25 | 252.00 |
| BED_26 | 333.00 |
| BED_27 | 375.00 |
| BED_3 | 127.00 |
| ... | ... |
| TSH_52 | 20.00 |
| TSH_53 | 21.00 |
| TSH_7 | 17.00 |
| TSH_8 | 18.00 |
| TSH_9 | 19.00 |
61 rows × 1 columns
In a similar way, we can enrich the data about the shops:
[27]:
shops_table = session.read_csv("data/shops.csv", keys=["Shop ID"])
shops_table.head()
[27]:
| City | State or region | Country | Shop size | |
|---|---|---|---|---|
| Shop ID | ||||
| shop_0 | New York | New York | USA | big |
| shop_1 | Los Angeles | California | USA | medium |
| shop_2 | San Diego | California | USA | medium |
| shop_3 | San Jose | California | USA | medium |
| shop_4 | San Francisco | California | USA | small |
[28]:
sales_table.join(shops_table, mapping={"Shop": "Shop ID"})
session.tables.schema
[28]:

New measures#
So far we have only used the default measures which are basic aggregations of the numeric columns. We can add new custom measures to our cube.
Max#
We’ll start with a simple aggregation taking the maximum price of the sales table:
[29]:
m["Max price"] = tt.agg.max(sales_table["Unit price"])
This new measure is directly available:
[30]:
cube.query(m["Max price"], include_totals=True, levels=[l["Category"]])
[30]:
| Max price | |
|---|---|
| Category | |
| Total | 440.00 |
| Cloth | 60.00 |
| Furniture | 440.00 |
Fact-level operations#
To compute aggregates based of data which comes directly from the columns of a table, you can pass the calculation directly to the desired aggregation function. This is more efficient than first converting the columns to measures before the aggregation.
Let’s use this to compute the total amount earned from the sale of the products, as well as the average.
Note the use of the origin scope instructing to perform the multiplication for each Sale ID and then do the sum.
[31]:
m["Amount.SUM"] = tt.agg.sum(
sales_table["Quantity"] * sales_table["Unit price"],
scope=tt.scope.origin(l["Sale ID"]),
)
m["Amount.MEAN"] = tt.agg.mean(
sales_table["Quantity"] * sales_table["Unit price"],
scope=tt.scope.origin(l["Sale ID"]),
)
We can now plot the evolution of the sales per country over time:
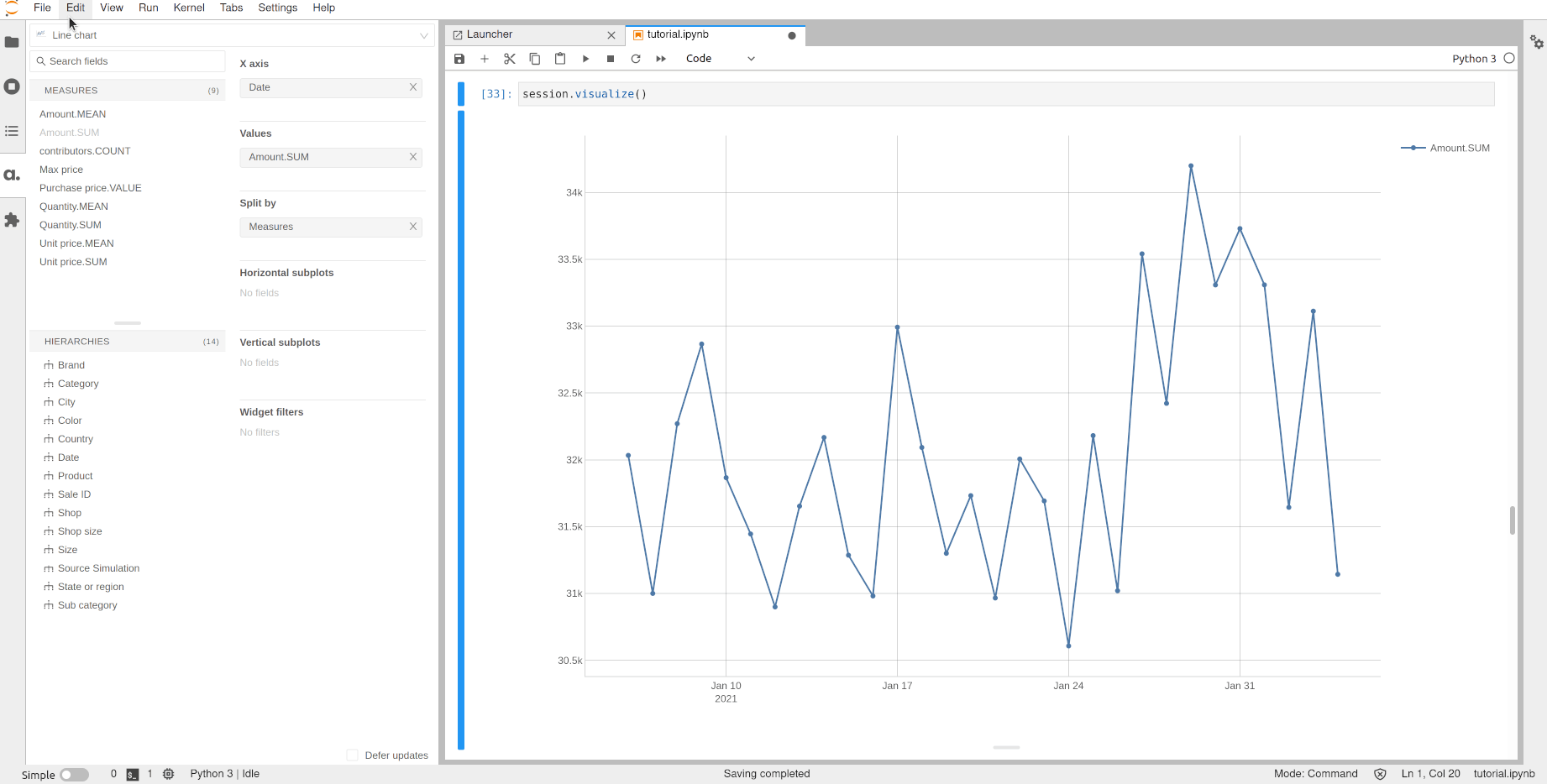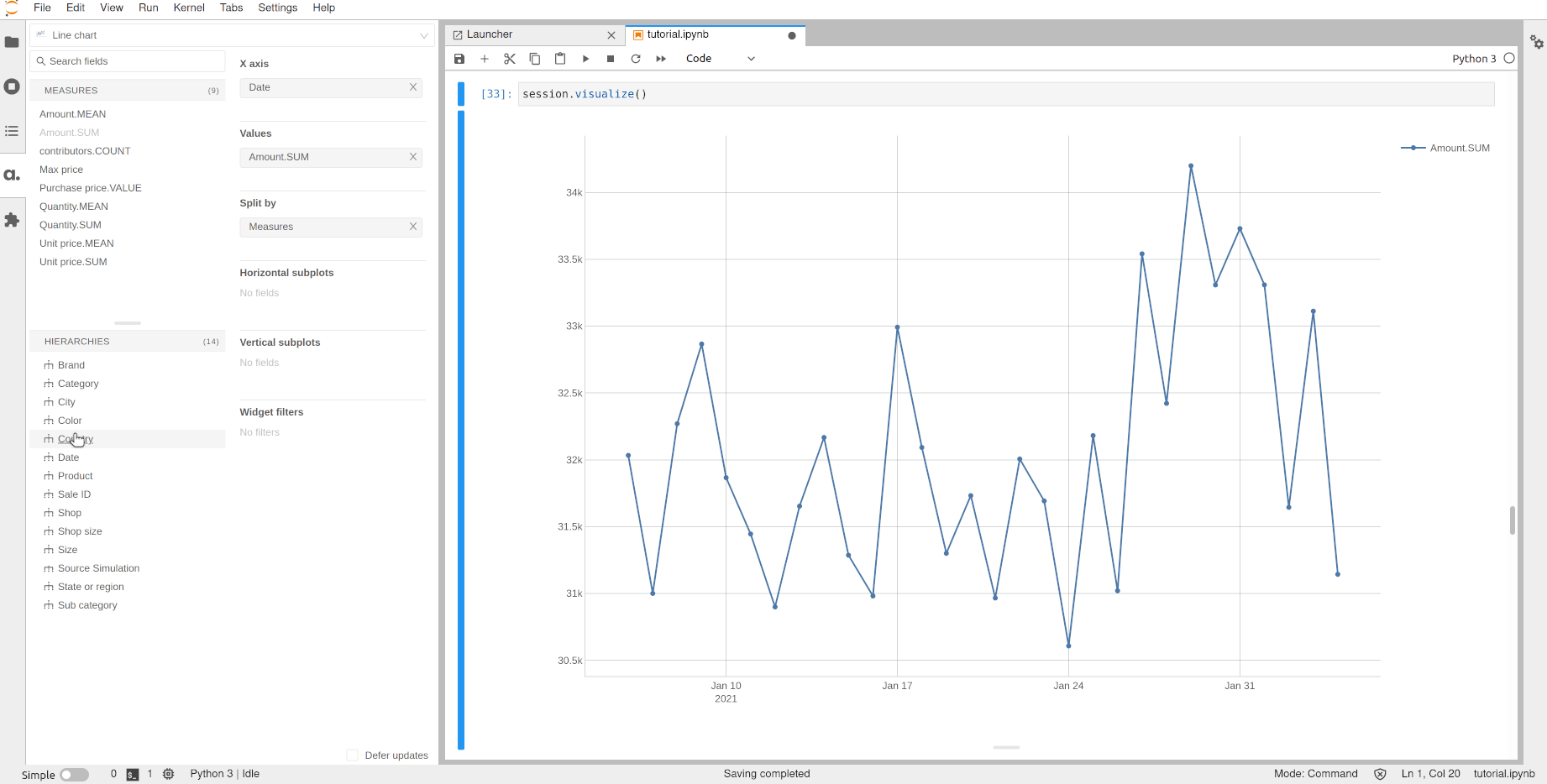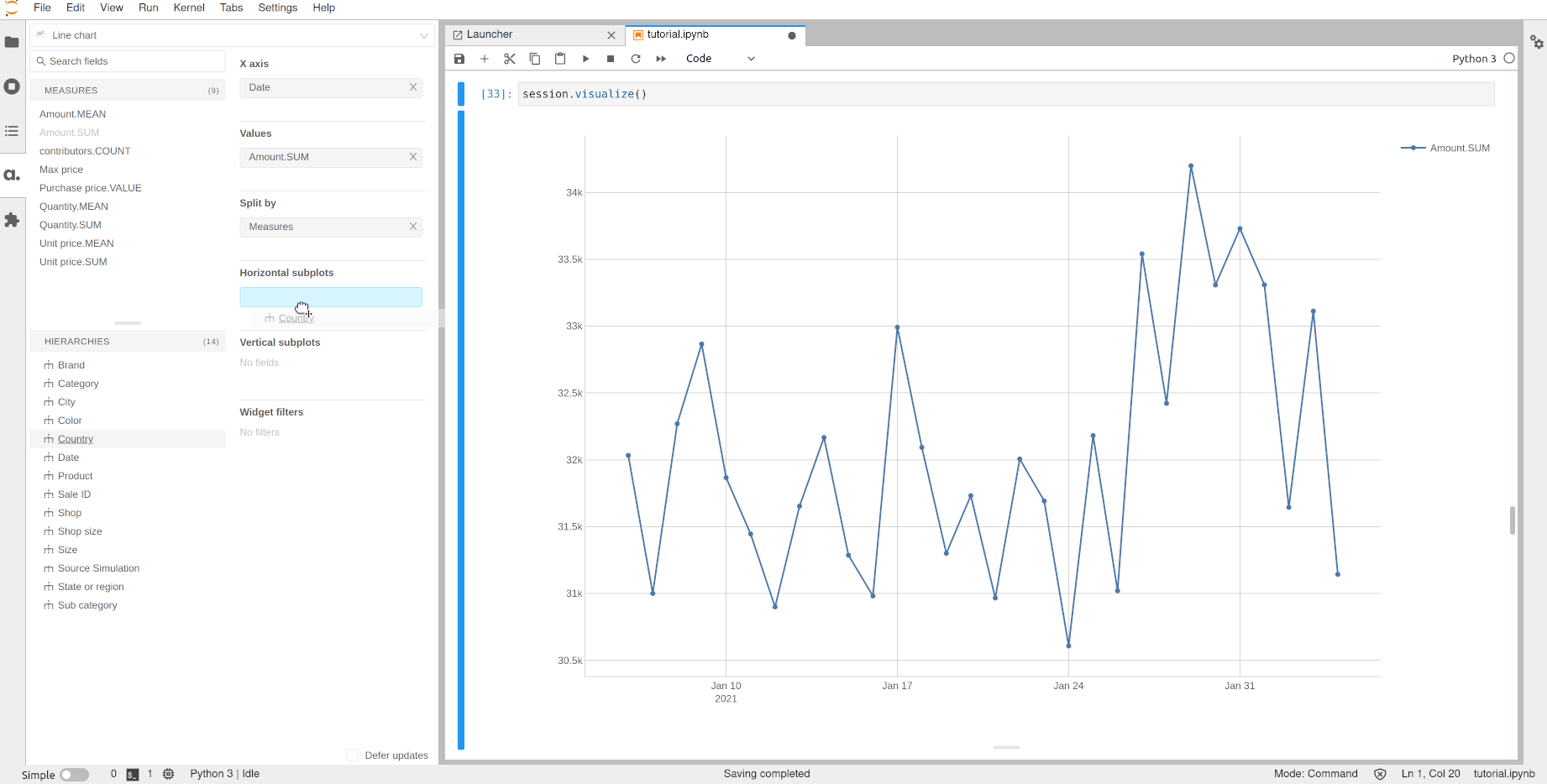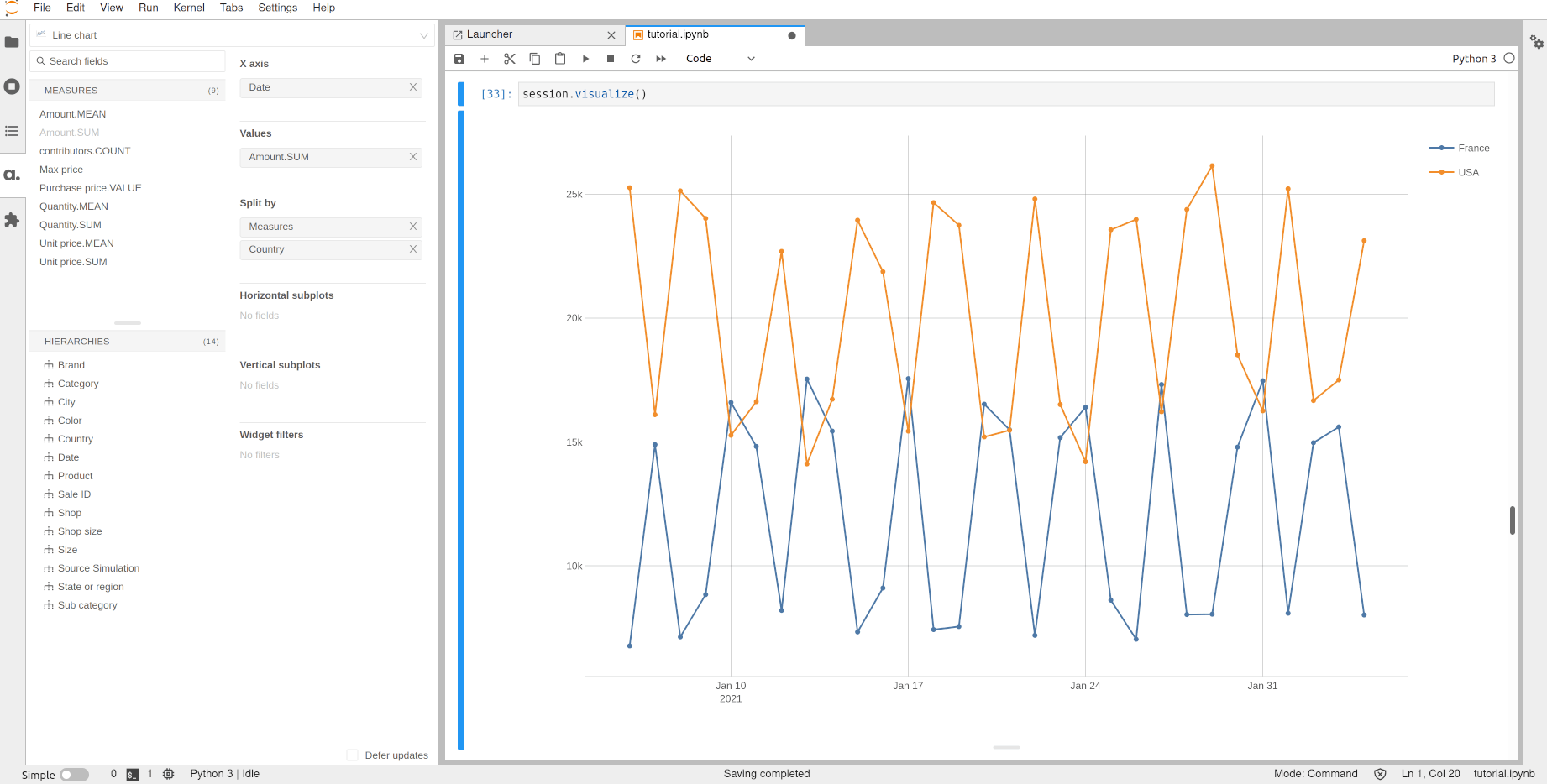
[32]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Margin#
Now that the price of each product is available from the products table, we can compute the margin.
To do that, we start by computing the cost which is the quantity sold multiplied by the purchase price, summed over all the products.
[33]:
cost = tt.agg.sum(
m["Quantity.SUM"] * tt.value(products_table["Purchase price"]),
scope=tt.scope.origin(l["Product"]),
)
[34]:
m["Margin"] = m["Amount.SUM"] - cost
We can also define the margin rate which is the ratio of the margin by the the sold amount:
[35]:
m["Margin rate"] = m["Margin"] / m["Amount.SUM"]
[36]:
cube.query(m["Margin"], m["Margin rate"], levels=[l["Product"]])
[36]:
| Margin | Margin rate | |
|---|---|---|
| Product | ||
| BED_24 | 3,082.00 | .15 |
| BED_25 | 6,336.00 | .16 |
| BED_26 | 8,060.00 | .16 |
| BED_27 | 8,580.00 | .15 |
| BED_3 | 3,036.00 | .15 |
| ... | ... | ... |
| TSH_52 | 520.00 | .17 |
| TSH_53 | 396.00 | .12 |
| TSH_7 | 393.00 | .15 |
| TSH_8 | 264.00 | .10 |
| TSH_9 | 390.00 | .14 |
61 rows × 2 columns
Let’s use this margin rate to do a Top 10 filter to see the products with the best rate.
Note that you don’t need to put the rate measure and the product level in the pivot table to apply the filter.
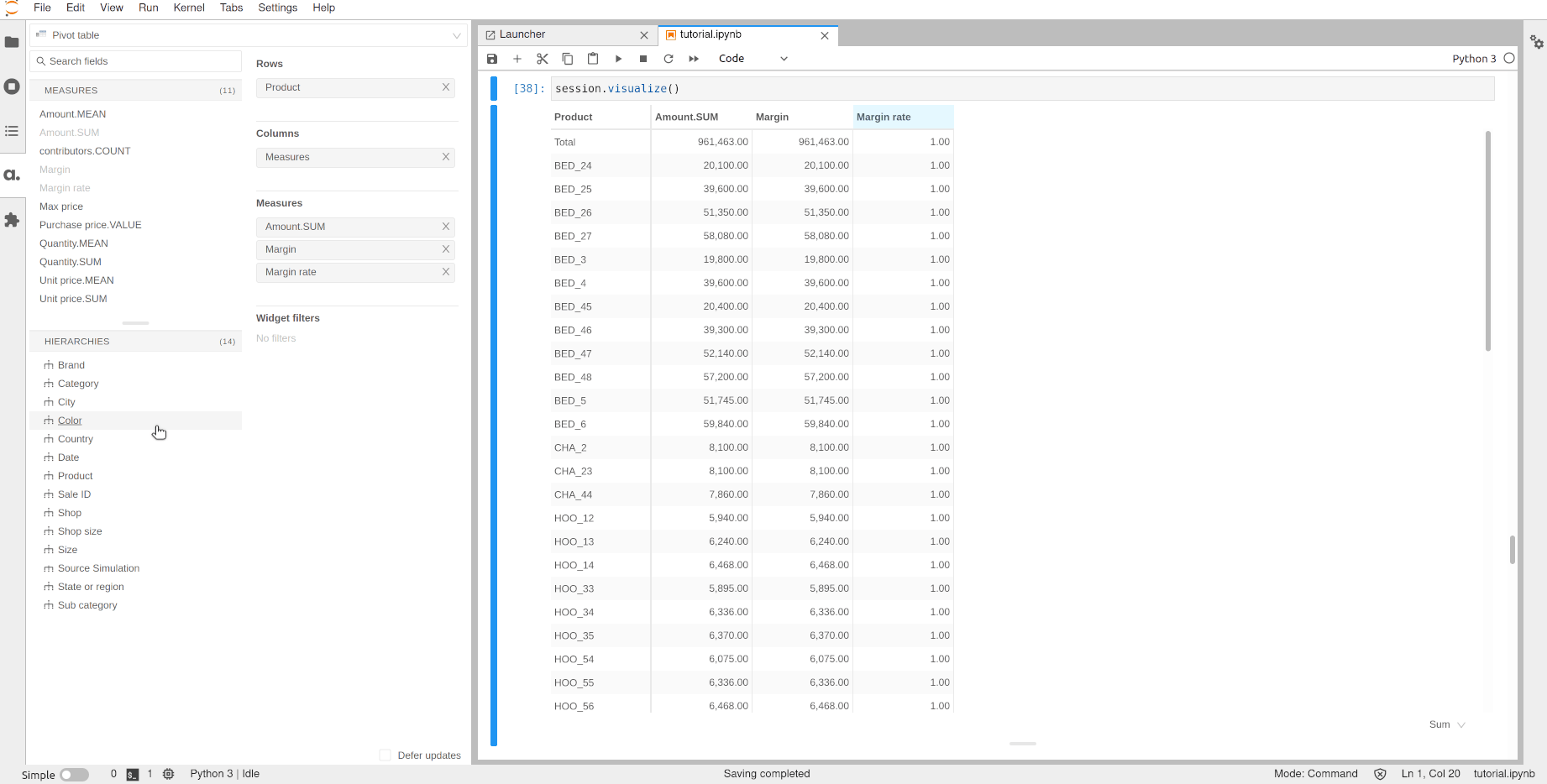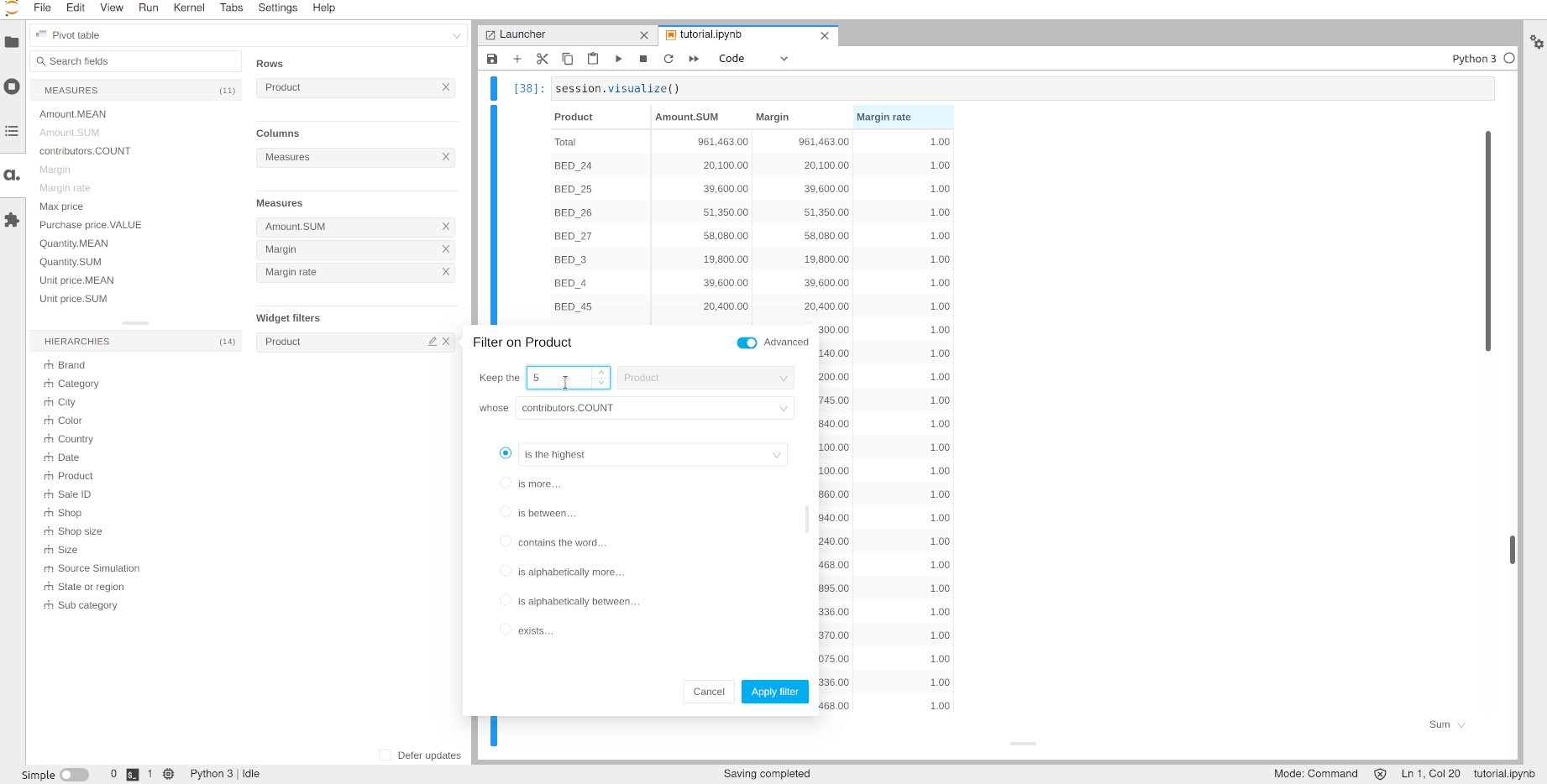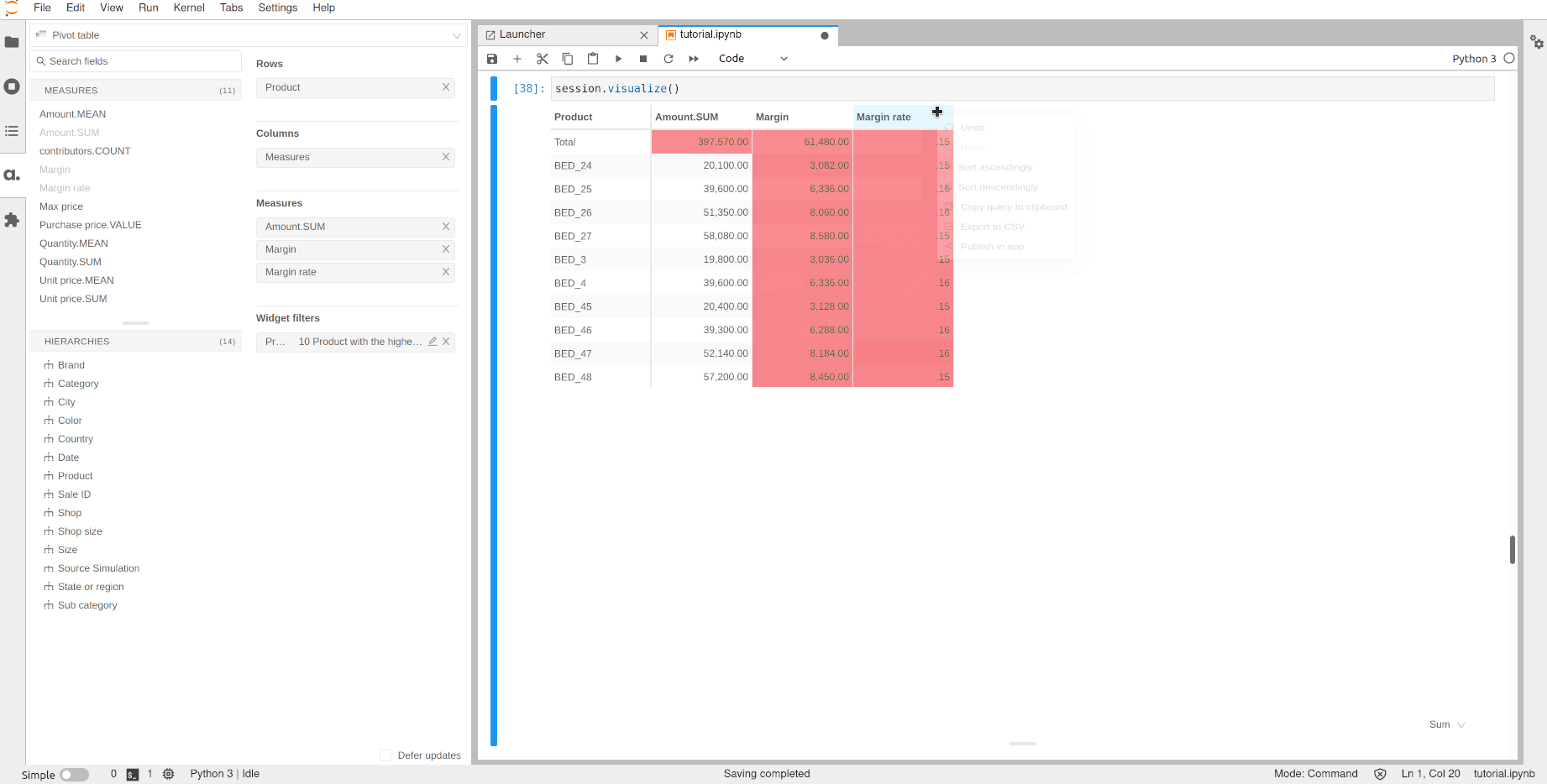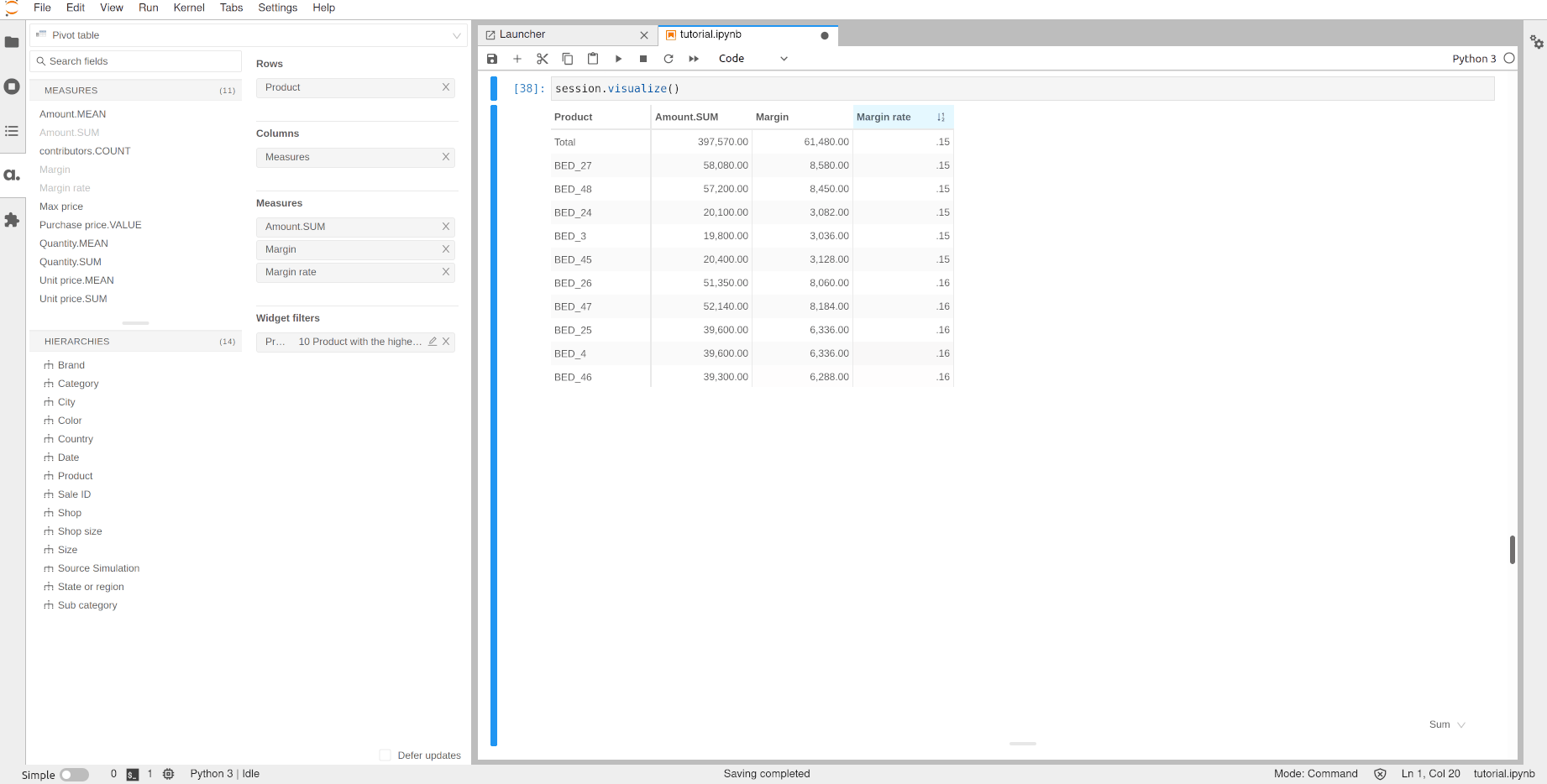
[37]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Cumulative sum over time#
A cumulative sum is the partial sum of the data up to the current value. For instance, a cumulative sum over time can be used to show how some measure changes over time.
[38]:
m["Cumulative amount"] = tt.agg.sum(
m["Amount.SUM"], scope=tt.scope.cumulative(l["Date"])
)
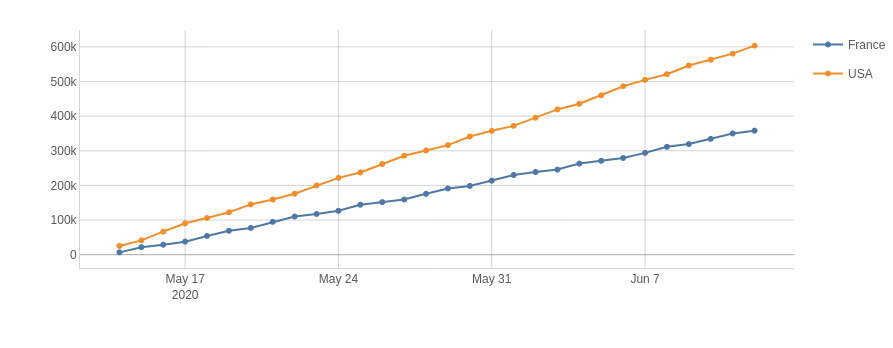
[39]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Average per shop#
Aggregations can also be combined. For instance, we can sum inside a Shop: then take the average of this to see how much a table sales on average:
[40]:
m["Average amount per shop"] = tt.agg.mean(
m["Amount.SUM"], scope=tt.scope.origin(l["Shop"])
)
[41]:
cube.query(
m["Average amount per shop"], include_totals=True, levels=[l["Sub category"]]
)
[41]:
| Average amount per shop | |
|---|---|
| Sub category | |
| Total | 192.29 |
| Bed | 517.43 |
| Chair | 97.80 |
| Hoodie | 76.05 |
| Shoes | 97.24 |
| Table | 408.41 |
| Tshirt | 35.61 |
Multilevel hierarchies#
So far, all our hierarchies only had one level but it’s best to regroup attributes with a parent-child relationship in the same hierarchy.
For example, we can group the Category, SubCategory and Product ID levels into a Product hierarchy:
[42]:
h["Product"] = [l["Category"], l["Sub category"], l["Product"]]
And let’s remove the old hierarchies:
[43]:
del h["Category"]
del h["Sub category"]
[44]:
h
[44]:
- Dimensions
- Products
- Brand
- Brand
- Color
- Color
- Product
- Category
- Sub category
- Product
- Size
- Size
- Brand
- Sales
- Date
- Date
- Product
- Product
- Sale ID
- Sale ID
- Shop
- Shop
- Date
- Shops
- City
- City
- Country
- Country
- Shop size
- Shop size
- State or region
- State or region
- City
- Products
We can also do it with City, State or Region and Country to build a Geography hierarchy.
Note that instead of using existing levels you can also define a hierarchy with the columns of the table the levels will be based on:
[45]:
h["Geography"] = [
shops_table["Country"],
shops_table["State or region"],
shops_table["City"],
]
del h["Country"]
del h["State or region"]
del h["City"]
As we are restructuring the hierarchies, let’s use this opportunity to also change the dimensions.
A dimension regroups hierarchies of the same concept.
To keep it simple here, we will simply move the new Geography hierarchy to its own dimension:
[46]:
h["Geography"].dimension = "Location"
h
[46]:
- Dimensions
- Location
- Geography
- Country
- State or region
- City
- Geography
- Products
- Brand
- Brand
- Color
- Color
- Product
- Category
- Sub category
- Product
- Size
- Size
- Brand
- Sales
- Date
- Date
- Product
- Product
- Sale ID
- Sale ID
- Shop
- Shop
- Date
- Shops
- Shop size
- Shop size
- Shop size
- Location
With that, we can define new measures taking advantage of the multilevel structure. For instance, we can create a measure indicating how much a product contributes to its subcategory:
[47]:
m["Parent category amount"] = tt.parent_value(
m["Amount.SUM"], degrees={h[("Products", "Product")]: 1}
)
[48]:
m["Percent of parent amount"] = m["Amount.SUM"] / m["Parent category amount"]
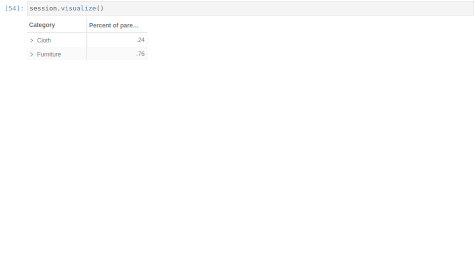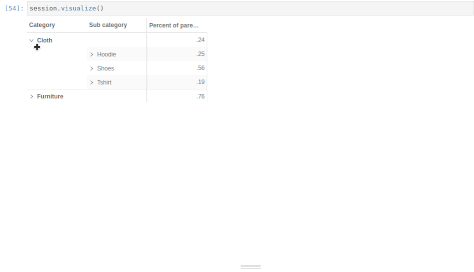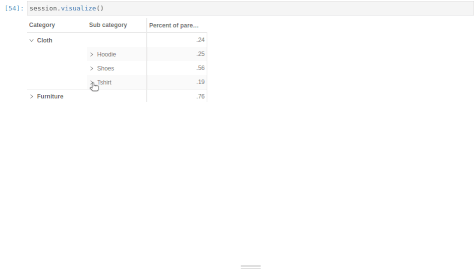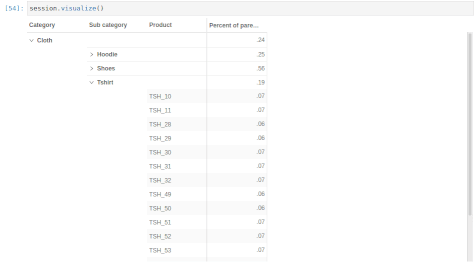
[49]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Polishing the cube#
Deleting or hiding measures#
Some measures have been automatically created from numeric columns but are not useful. For instance, Unit Price.SUM does not really make sense as we never want to sum the unit prices. We can delete it:
[50]:
del m["Unit price.SUM"]
Other measures have been used while building the project only as intermediary steps but are not useful to the end users in the application. We can hide them from the UI (they will remain accessible in Python):
[51]:
m["Parent category amount"].visible = False
Measure folders#
Measures can be rearranged into folders.
[52]:
for measure in [
m["Amount.MEAN"],
m["Amount.SUM"],
m["Average amount per shop"],
m["Cumulative amount"],
m["Percent of parent amount"],
]:
measure.folder = "Amount"
[53]:
m
[53]:
- Measures
- 📁 Amount
- Amount.MEAN
- formatter: DOUBLE[#,###.00]
- Amount.SUM
- formatter: DOUBLE[#,###.00]
- Average amount per shop
- formatter: DOUBLE[#,###.00]
- Cumulative amount
- formatter: DOUBLE[#,###.00]
- Percent of parent amount
- formatter: DOUBLE[#,###.00]
- Amount.MEAN
- Margin
- formatter: DOUBLE[#,###.00]
- Margin rate
- formatter: DOUBLE[#,###.00]
- Max price
- formatter: DOUBLE[#,###.00]
- Purchase price.VALUE
- formatter: DOUBLE[#,###.00]
- Quantity.MEAN
- formatter: DOUBLE[#,###.00]
- Quantity.SUM
- formatter: DOUBLE[#,###.00]
- Unit price.MEAN
- formatter: DOUBLE[#,###.00]
- contributors.COUNT
- formatter: INT[#,###]
- 📁 Amount
Measure formatters#
Some measures can be formatted for a nicer display. Classic examples of this is changing the number of decimals or adding a percent or a currency symbol.
Let’s do this for our percent of parent amount and margin rate:
Before#
[54]:
cube.query(m["Percent of parent amount"], m["Margin rate"], levels=[l["Category"]])
[54]:
| Percent of parent amount | Margin rate | |
|---|---|---|
| Category | ||
| Cloth | .24 | .23 |
| Furniture | .76 | .13 |
[55]:
m["Percent of parent amount"].formatter = "DOUBLE[0.00%]"
m["Margin rate"].formatter = "DOUBLE[0.00%]"
After#
[56]:
cube.query(m["Percent of parent amount"], m["Margin rate"], levels=[l["Category"]])
[56]:
| Percent of parent amount | Margin rate | |
|---|---|---|
| Category | ||
| Cloth | 23.64% | 22.56% |
| Furniture | 76.36% | 13.49% |
Simulations#
Simulations are a way to compare several scenarios and do what-if analysis. This helps understanding how changing the source data or a piece of the model impact the key indicators.
In atoti, the data model is made of measures chained together. A simulation can be seen as changing one part of the model, either its source data or one of its measure definitions, and then evaluating how it impacts the following measures.
Source simulation#
Let’s start by changing the source. With pandas or Spark, if you want to compare two results for a different versions of the entry dataset you have to reapply all the transformations to your dataset. With atoti, you only have to provide the new data and all the measures will be automatically available for both versions of the data.
We will create a new scenario using pandas to modify the original dataset.
[57]:
import pandas as pd
For instance, we can simulate what would happen if we had managed to purchase some products at a cheaper price.
[58]:
products_df = pd.read_csv("data/products.csv")
products_df.head()
[58]:
| Product | Category | Sub category | Size | Purchase price | Color | Brand | |
|---|---|---|---|---|---|---|---|
| 0 | TAB_0 | Furniture | Table | 1m80 | 190.0 | black | Basic |
| 1 | TAB_1 | Furniture | Table | 2m40 | 280.0 | white | Mega |
| 2 | CHA_2 | Furniture | Chair | NaN | 48.0 | blue | Basic |
| 3 | BED_3 | Furniture | Bed | Single | 127.0 | red | Mega |
| 4 | BED_4 | Furniture | Bed | Double | 252.0 | brown | Basic |
[59]:
better_prices = {
"TAB_0": 180.0,
"TAB_1": 250.0,
"CHA_2": 40.0,
"BED_3": 110.0,
"BED_4": 210.0,
}
[60]:
for product, purchase_price in better_prices.items():
products_df.loc[
products_df["Product"] == product, "Purchase price"
] = purchase_price
products_df.head()
[60]:
| Product | Category | Sub category | Size | Purchase price | Color | Brand | |
|---|---|---|---|---|---|---|---|
| 0 | TAB_0 | Furniture | Table | 1m80 | 180.0 | black | Basic |
| 1 | TAB_1 | Furniture | Table | 2m40 | 250.0 | white | Mega |
| 2 | CHA_2 | Furniture | Chair | NaN | 40.0 | blue | Basic |
| 3 | BED_3 | Furniture | Bed | Single | 110.0 | red | Mega |
| 4 | BED_4 | Furniture | Bed | Double | 210.0 | brown | Basic |
We can now load this new dataframe into a new scenarios of the products table.
[61]:
products_table.scenarios["Cheaper purchase prices"].load_pandas(products_df)
The session now has two scenarios and the only differences between them are the lines corresponding to the products with better prices, everything else is shared between the scenarios and has not been duplicated: source scenarios in atoti are memory-efficient.

Using the Source Simulation hierarchy we can display the margin of the scenario and compare it to the base case.
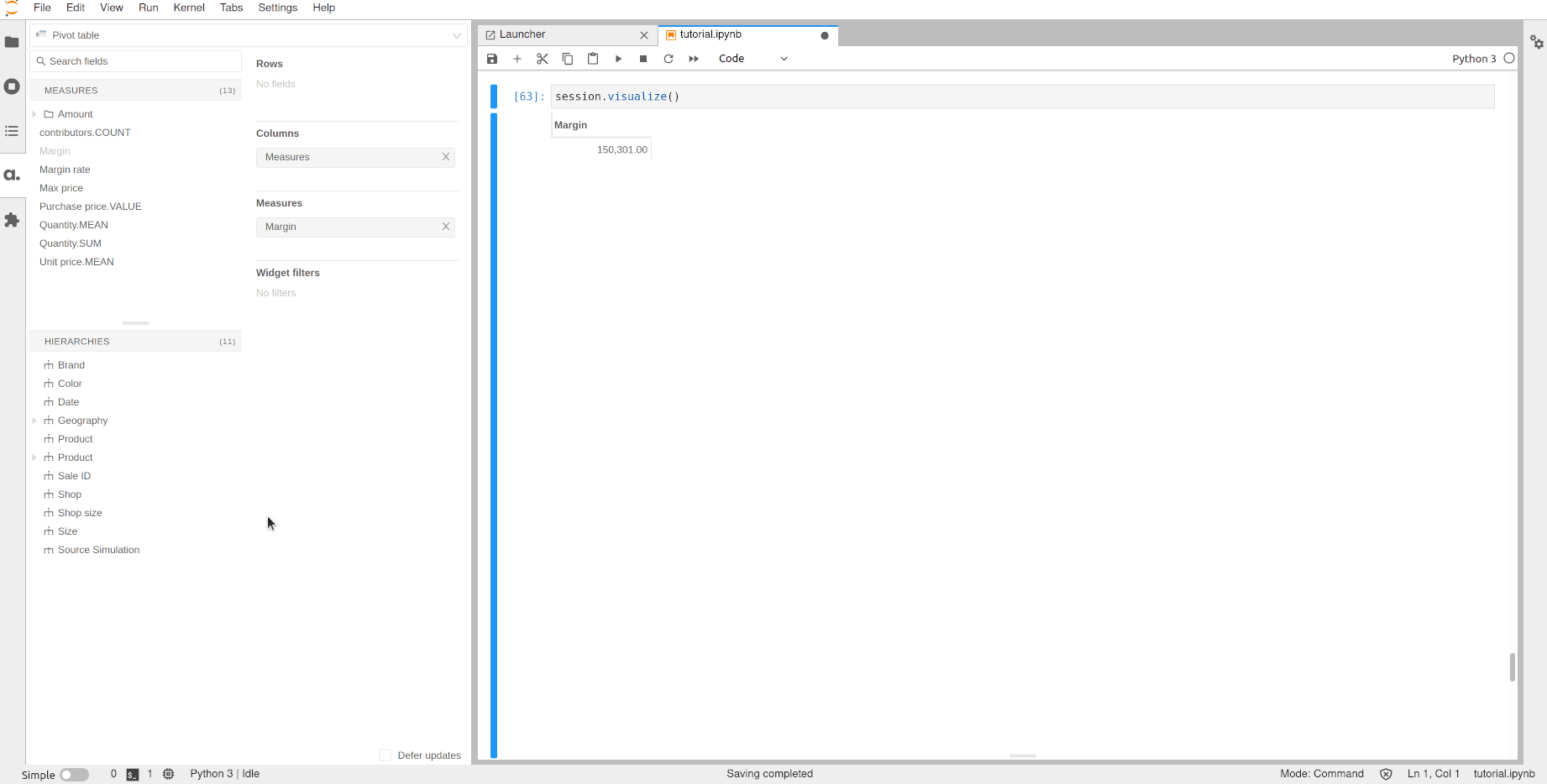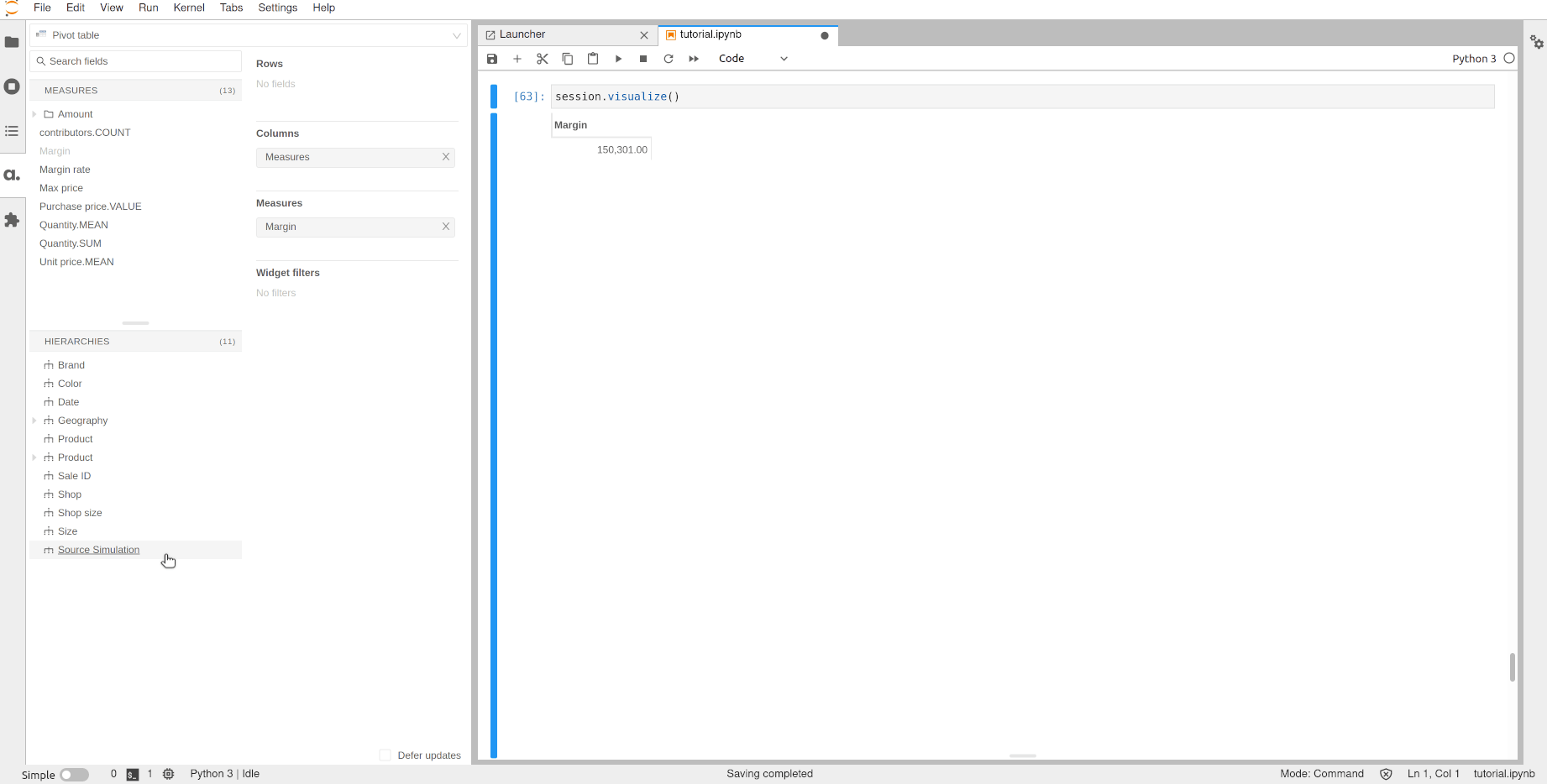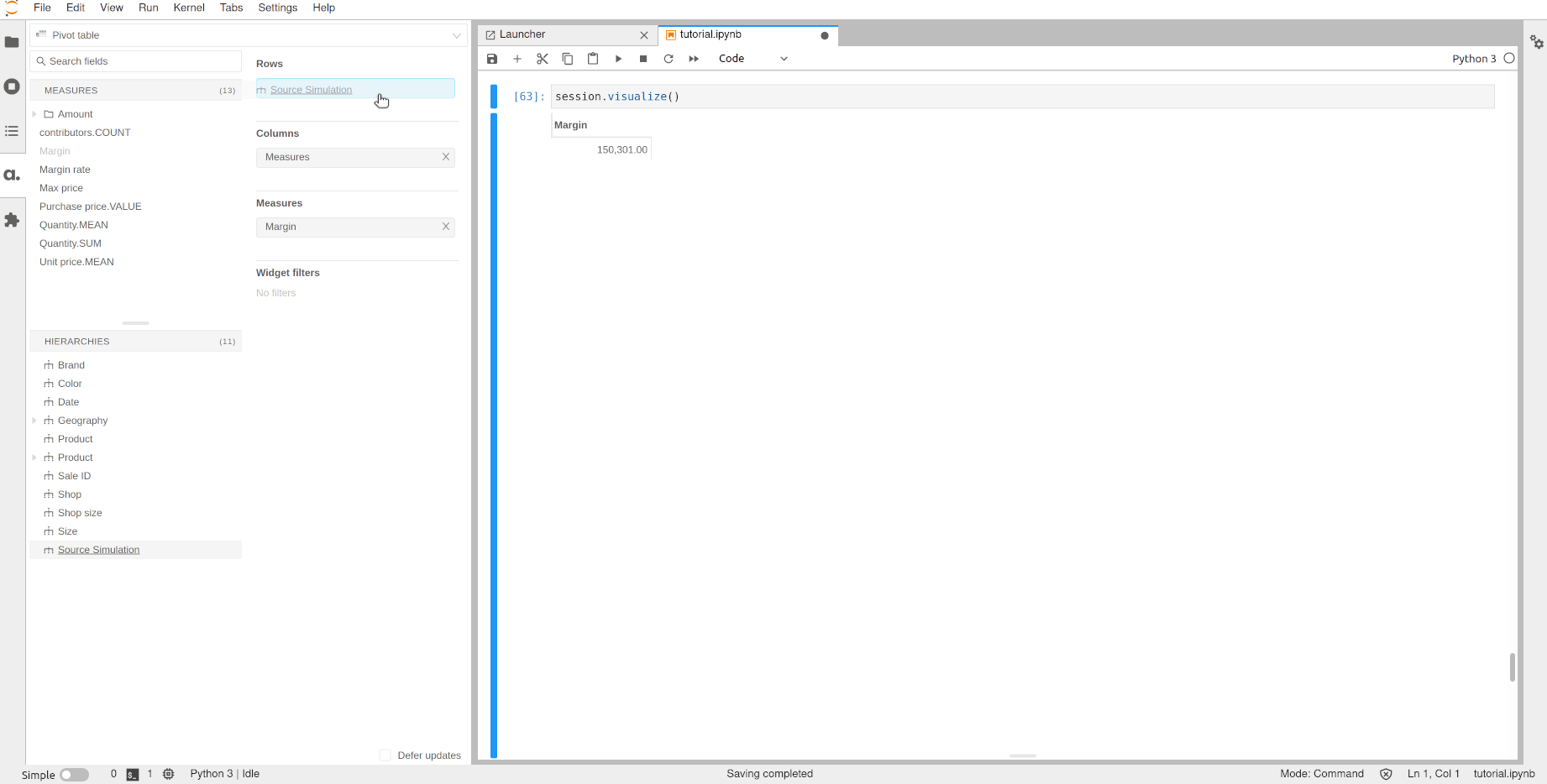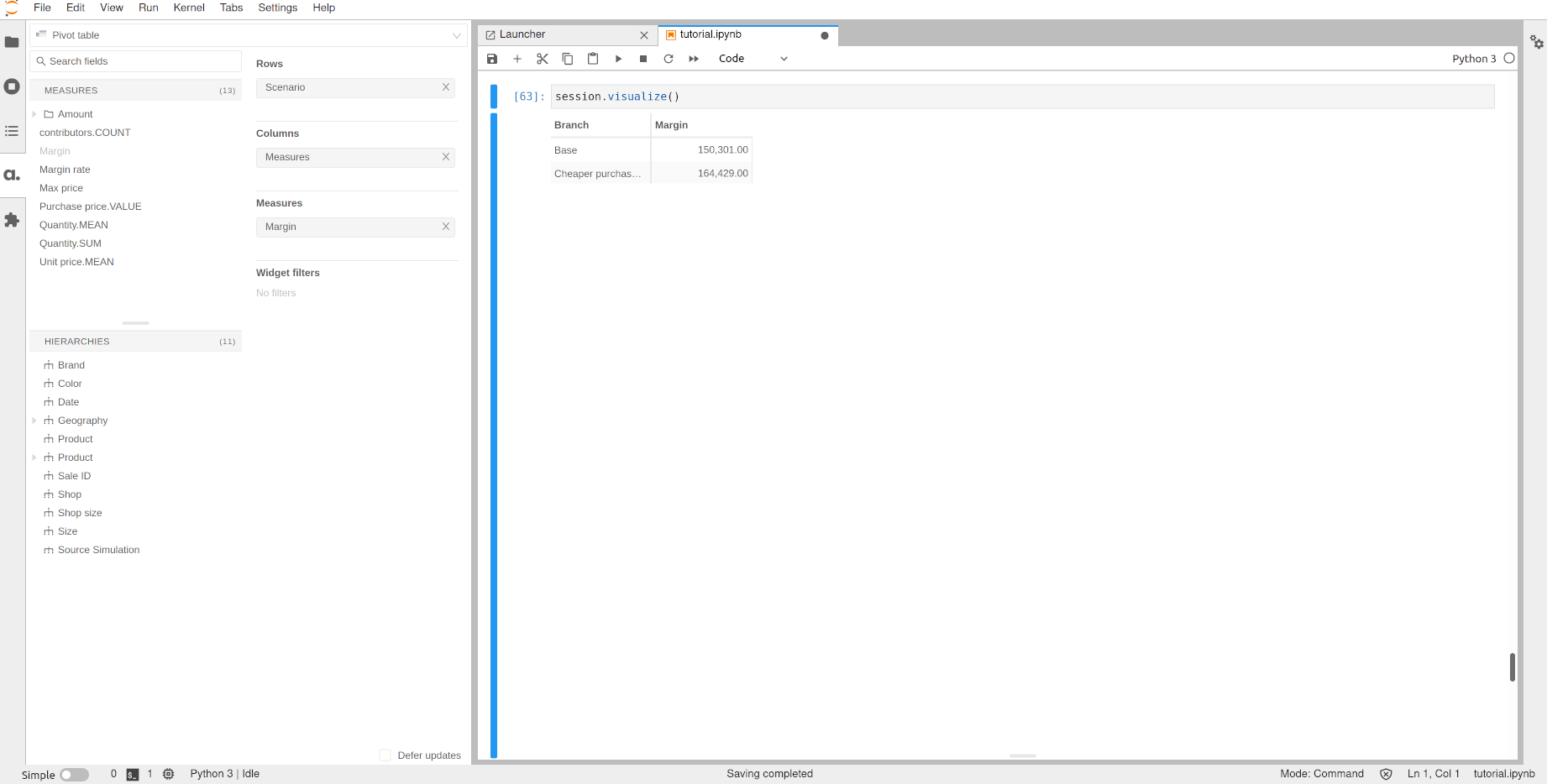
[62]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Note that all the existing measures are immediately available on the new data. For instance, the margin rate still exists, and we can see that in this scenario we would have a better margin for the Furniture products.
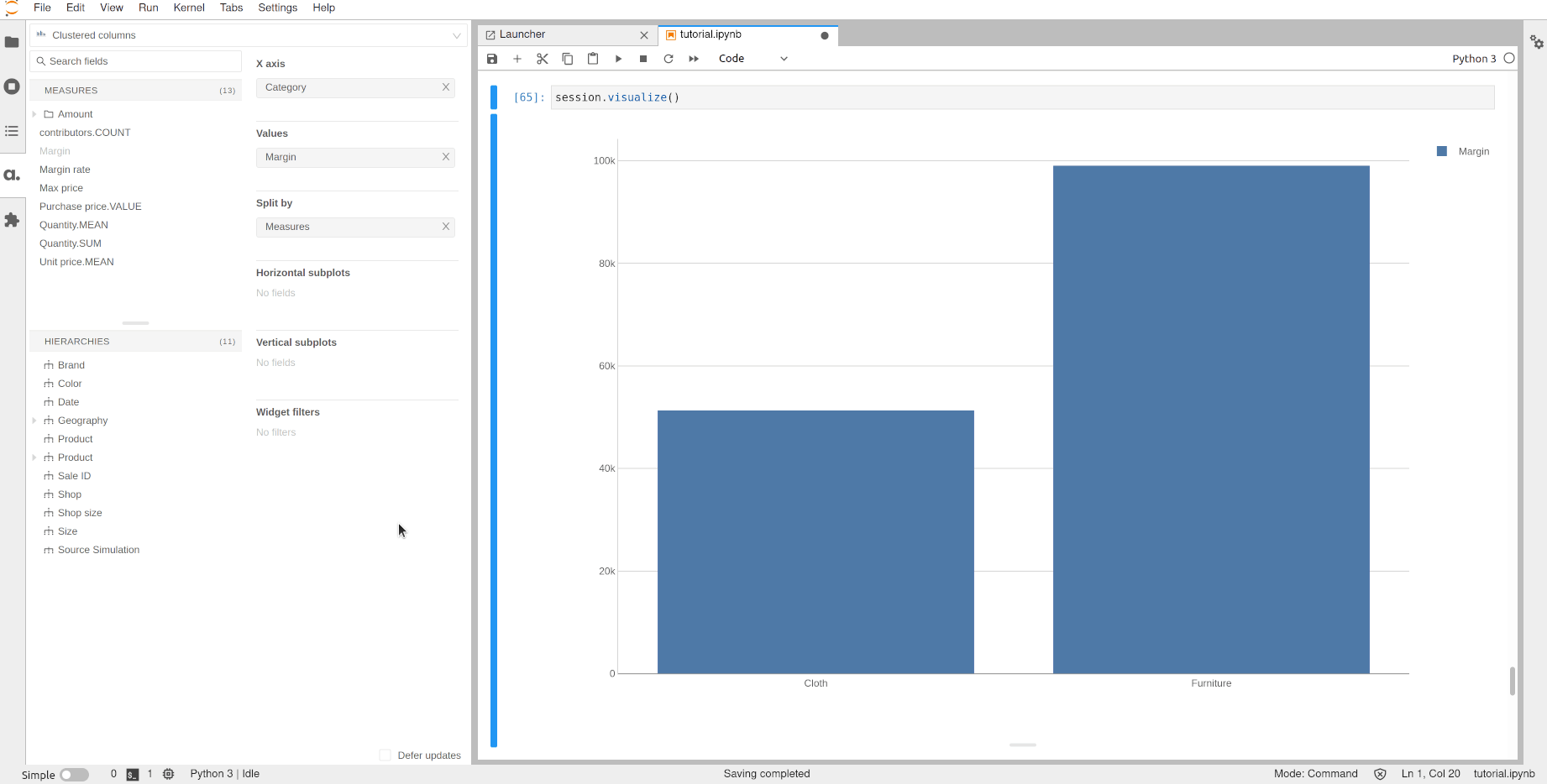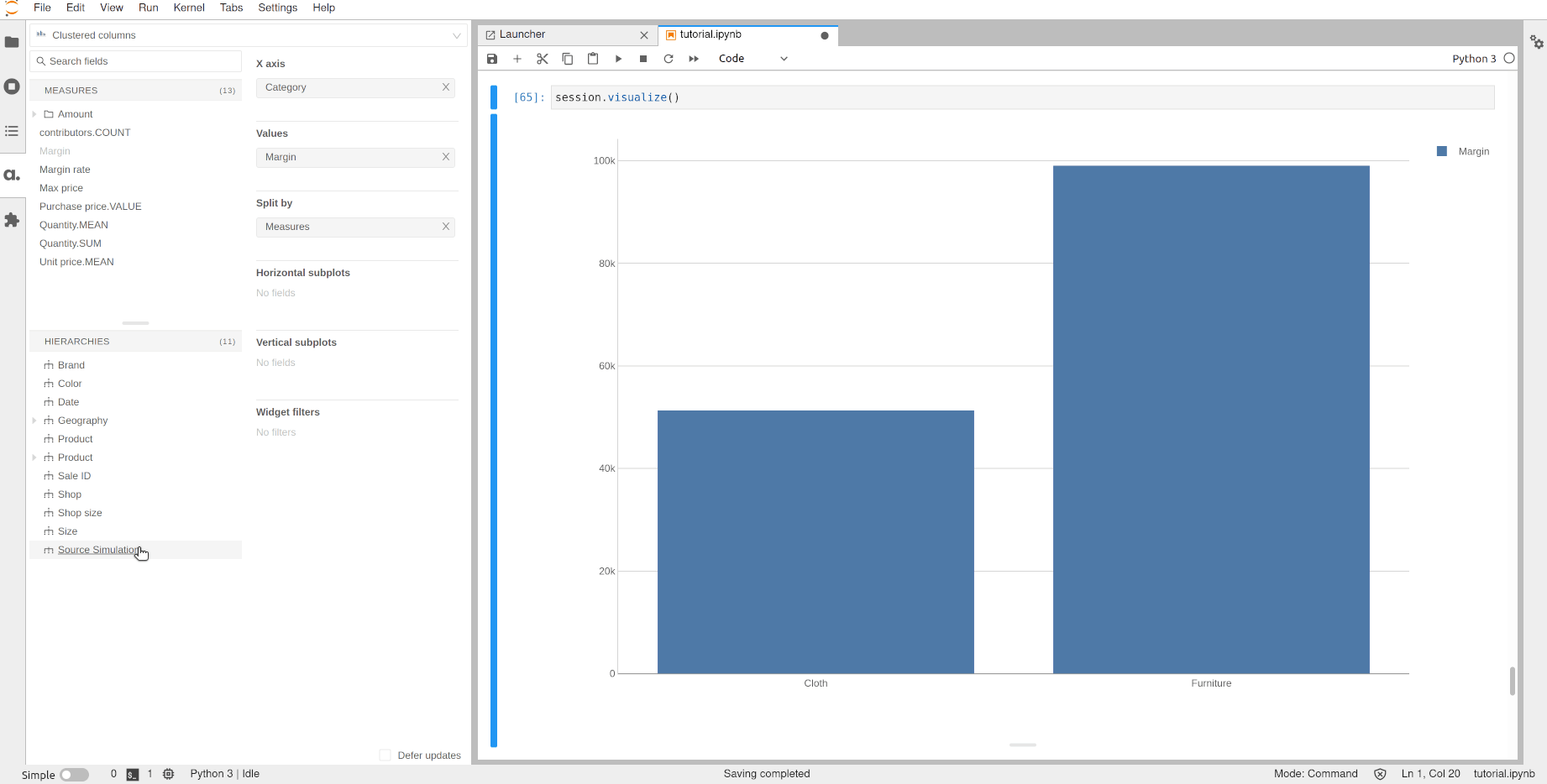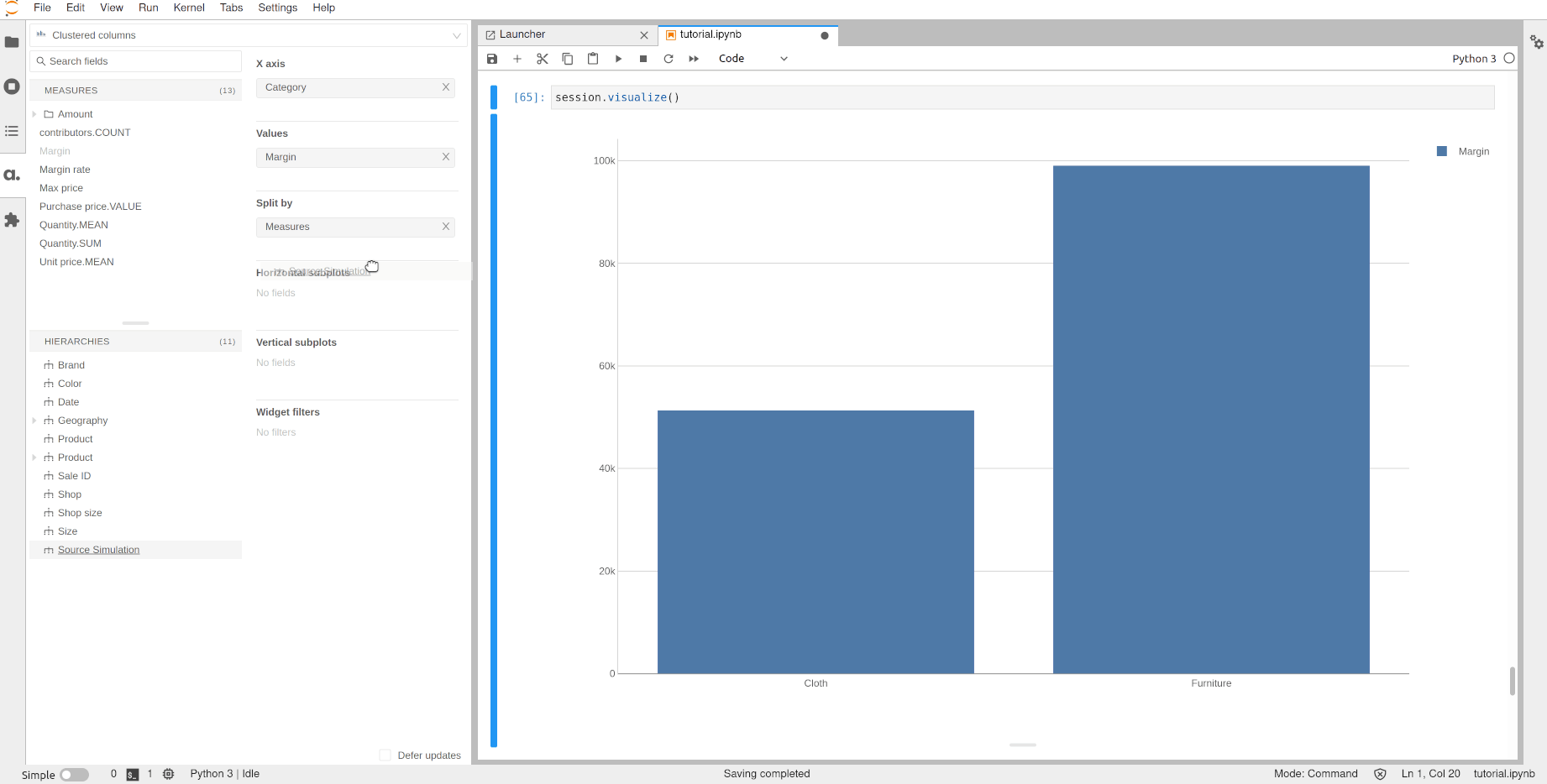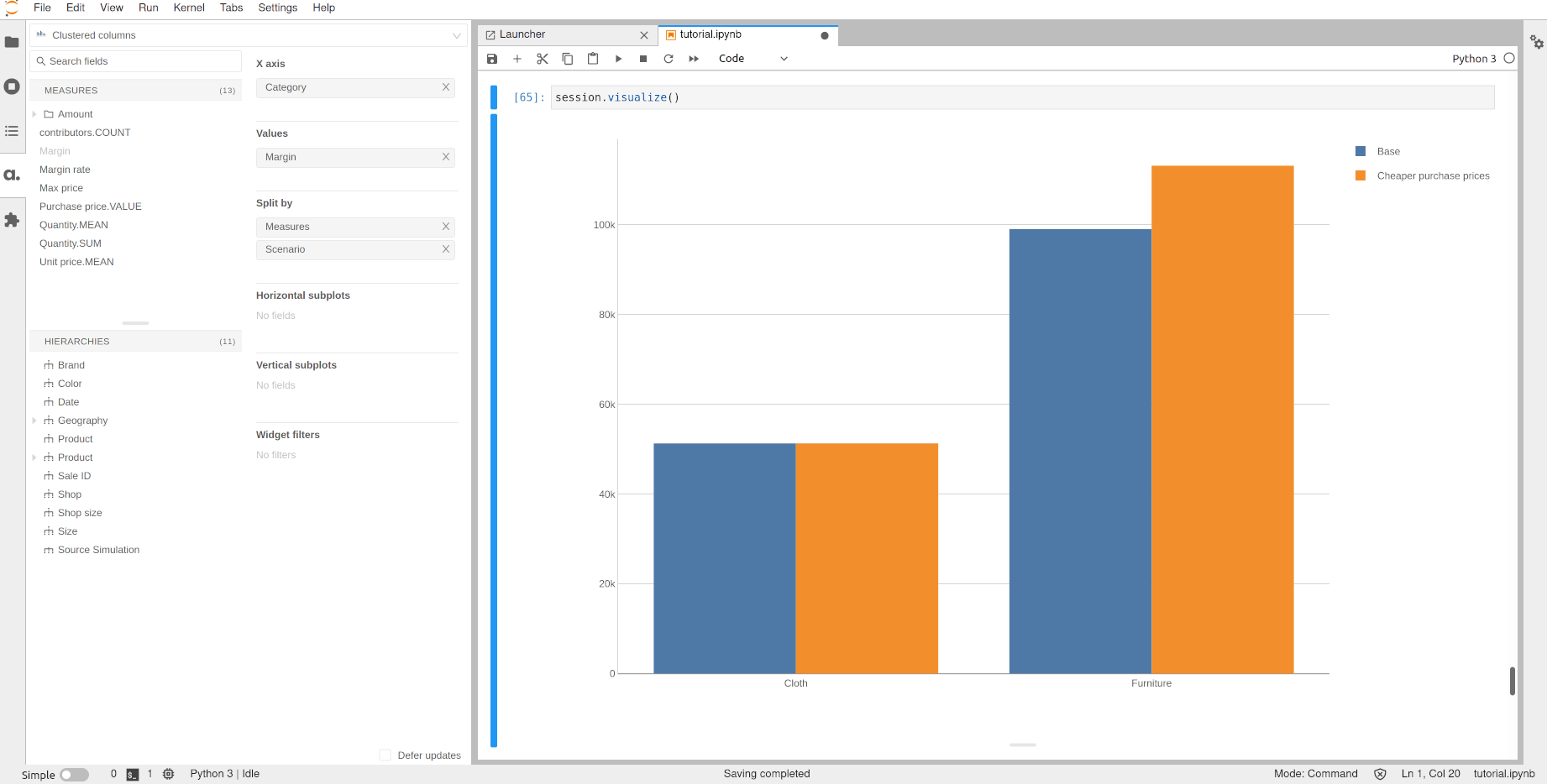
[63]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Parameter simulations#
The other simulation technique is to create a parameter measure whose value can be changed for some coordinates.
When creating the simulation, you can choose at which granularity the modification applies. For instance we can create a parameter measure whose value will change depending on the country. Doing that, we can answer questions such as “What happens if there is a crisis in France and we sell 20% less?”
[64]:
country_simulation = cube.create_parameter_simulation(
"Country Simulation",
levels=[l["Country"]],
measures={"Country parameter": 1.0},
)
This has created a measure named Country parameter and added it to the cube. For now, its value is 1 everywhere, but using the country_simulation we can change that.
By adding values in the table you can change the value of the parameter measure depending on the levels used in the simulation and the scenario.
[65]:
country_simulation += ("France Crisis", "France", 0.80)
country_simulation.head()
[65]:
| Country parameter | ||
|---|---|---|
| Scenario | Country | |
| France Crisis | France | 0.8 |
Let’s replace the existing Quantity.SUM and Amount.SUM measures with new ones using the parameter measure from the simulation.
[66]:
m["Quantity.SUM"] = tt.agg.sum(
tt.agg.sum(sales_table["Quantity"]) * m["Country parameter"],
scope=tt.scope.origin(l["Country"]),
)
m["Amount.SUM"] = tt.agg.sum(
tt.agg.sum(sales_table["Unit price"] * sales_table["Quantity"])
* m["Country parameter"],
scope=tt.scope.origin(l["Country"]),
)
We can query the cube using the new Country Simulation level to compare the quantity and amount between the base case and our new scenario:
[67]:
cube.query(
m["Quantity.SUM"],
m["Amount.SUM"],
include_totals=True,
levels=[l["Country Simulation"], l["Country"]],
)
[67]:
| Quantity.SUM | Amount.SUM | ||
|---|---|---|---|
| Country Simulation | Country | ||
| Base | 8,077.00 | 961,463.00 | |
| France | 3,027.00 | 358,042.00 | |
| USA | 5,050.00 | 603,421.00 | |
| France Crisis | 7,471.60 | 889,854.60 | |
| France | 2,421.60 | 286,433.60 | |
| USA | 5,050.00 | 603,421.00 |
Here for example, as the amount has been modified, the measures depending on it such as the cumulative amount are also impacted:
[68]:
cube.query(m["Cumulative amount"], levels=[l["Country Simulation"], l["Country"]])
[68]:
| Cumulative amount | ||
|---|---|---|
| Country Simulation | Country | |
| Base | France | 358,042.00 |
| USA | 603,421.00 | |
| France Crisis | France | 286,433.60 |
| USA | 603,421.00 |
Let’s try adding a different scenario:
[69]:
country_simulation += ("US boost", "USA", 1.15)
[70]:
cube.query(m["Quantity.SUM"], levels=[l["Country Simulation"], l["Country"]])
[70]:
| Quantity.SUM | ||
|---|---|---|
| Country Simulation | Country | |
| Base | France | 3,027.00 |
| USA | 5,050.00 | |
| France Crisis | France | 2,421.60 |
| USA | 5,050.00 | |
| US boost | France | 3,027.00 |
| USA | 5,807.50 |
The two scenarios can be visualized in the same widget:
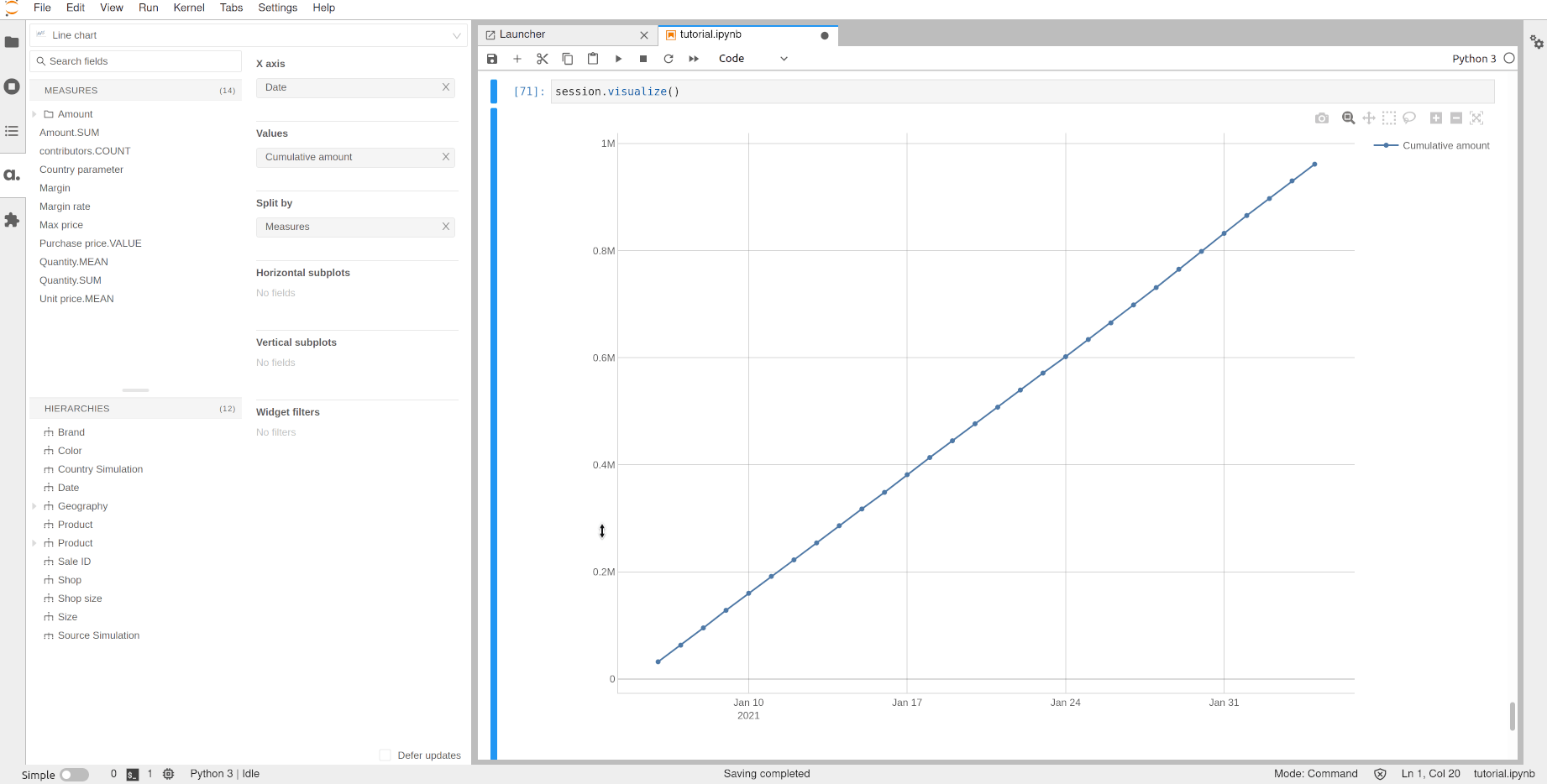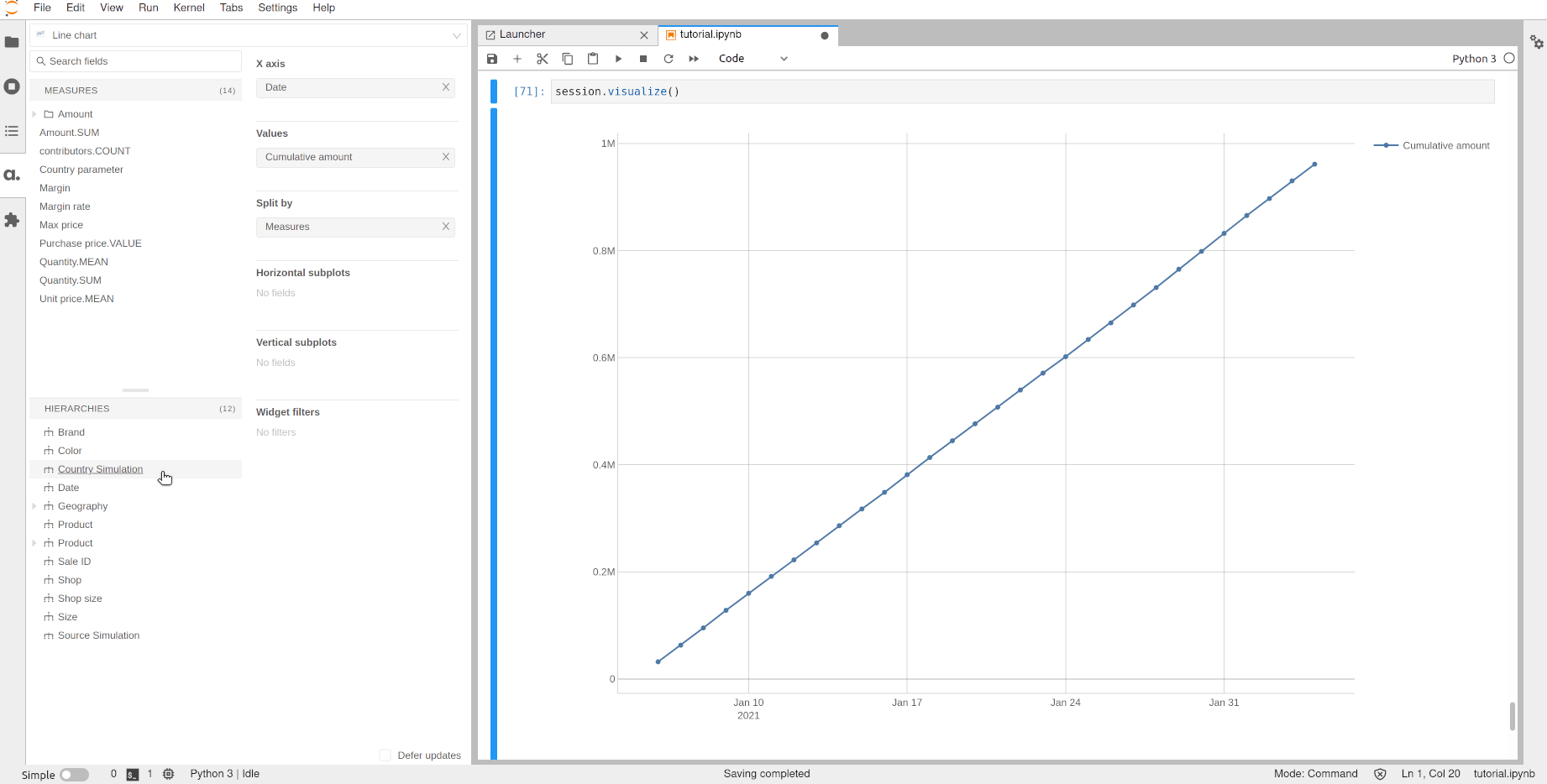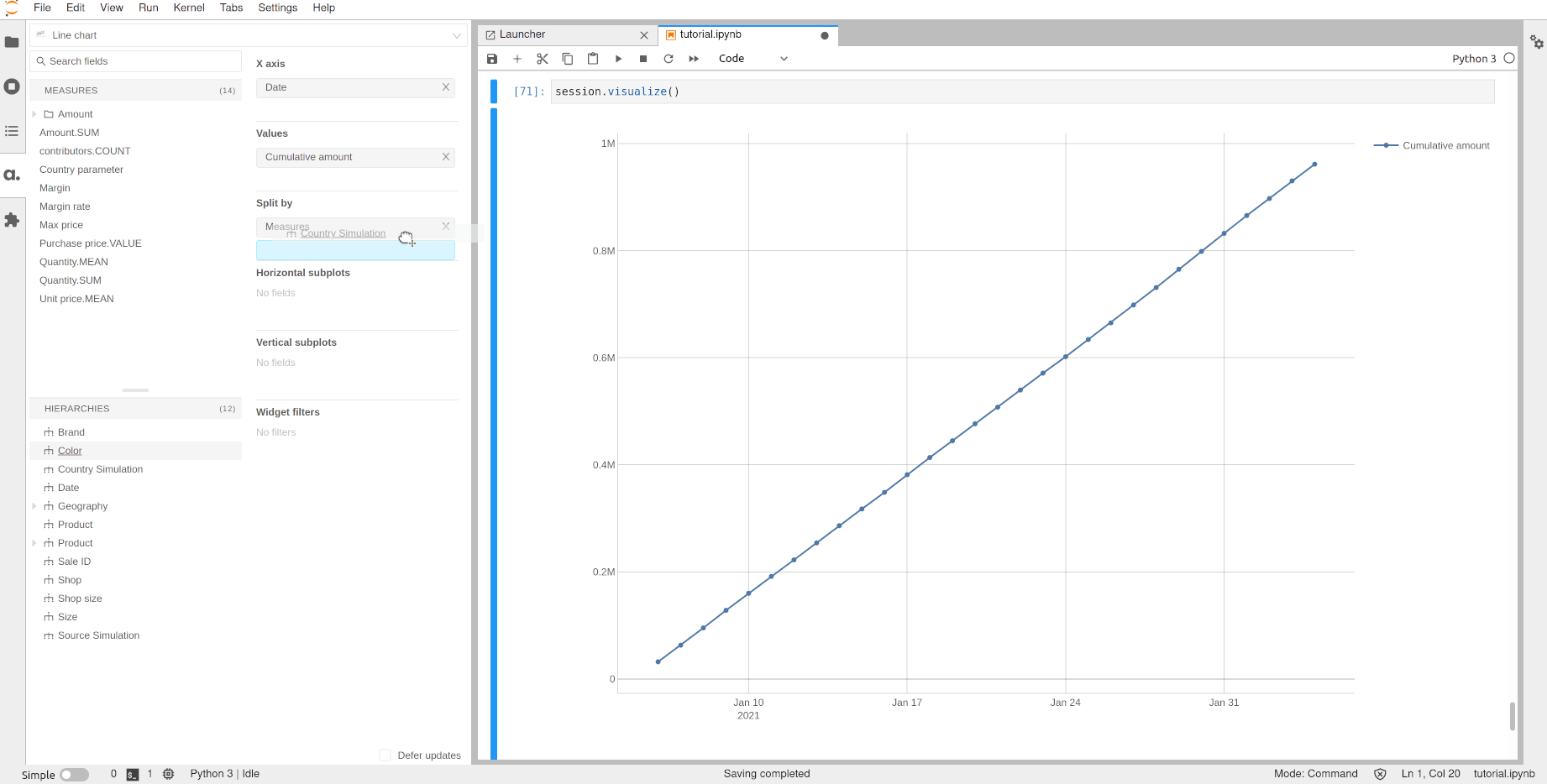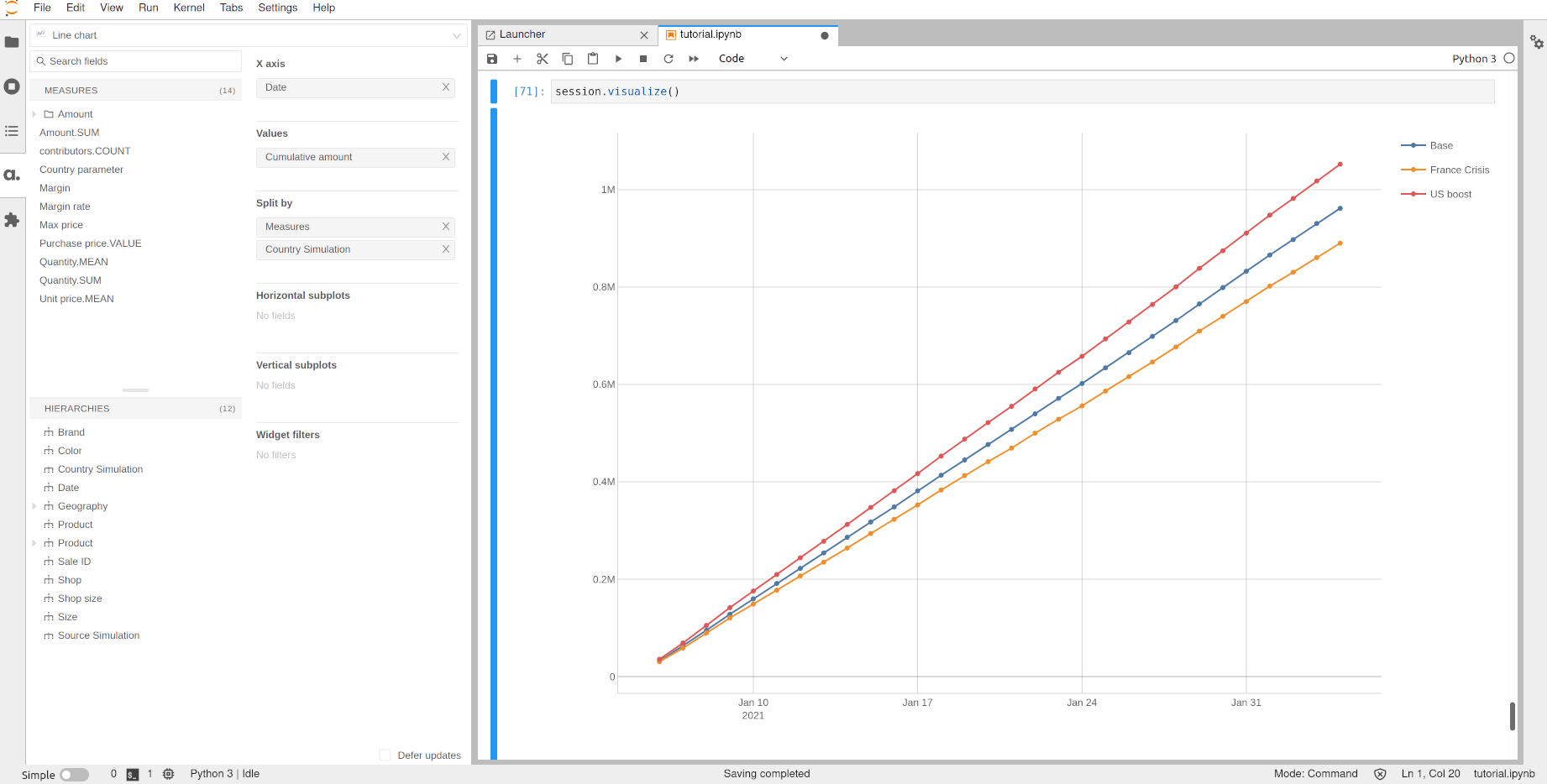
[71]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Finally, we can even combine the different simulations (the source one and the measure one) to create a matrix of scenarios:
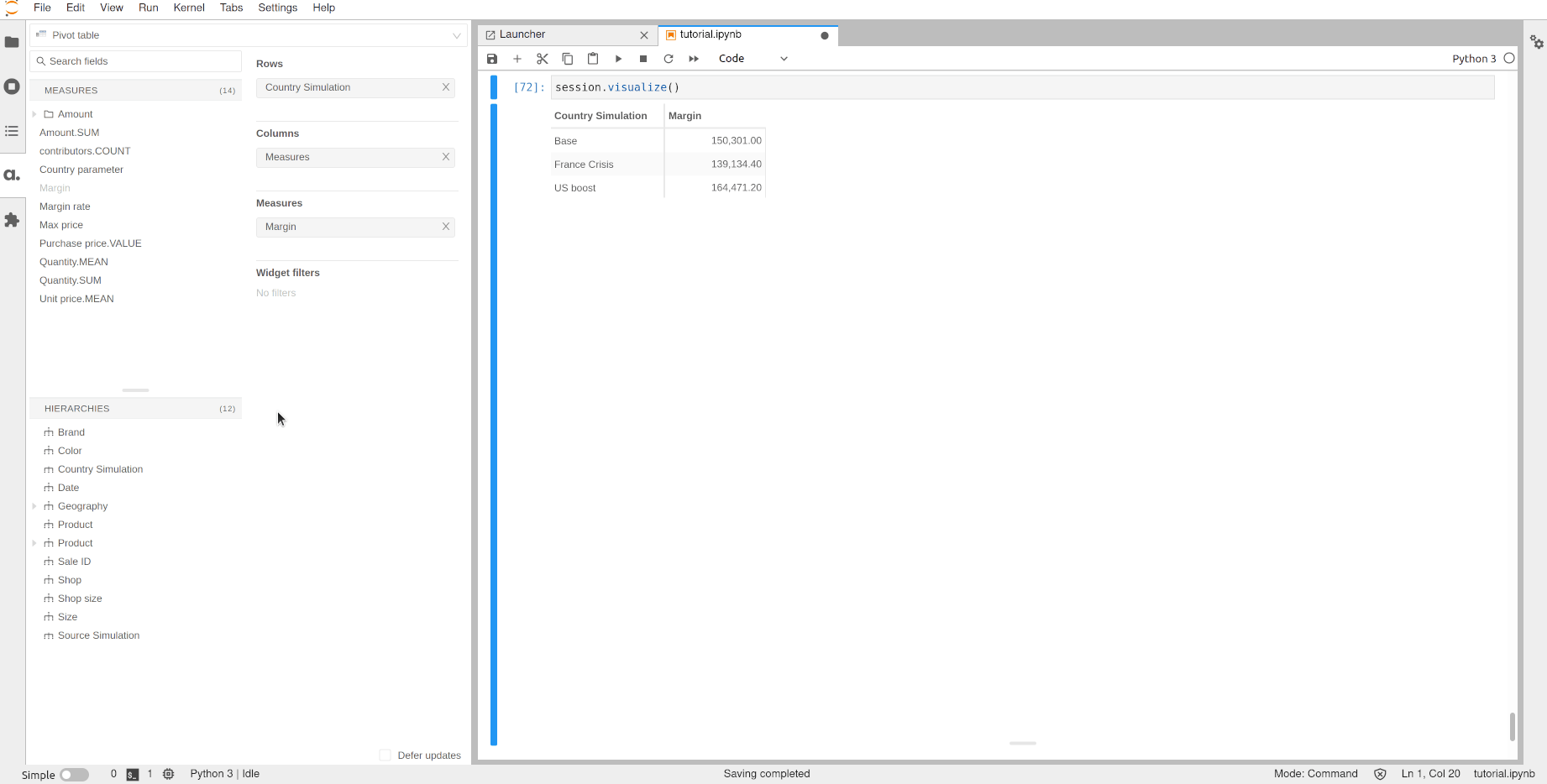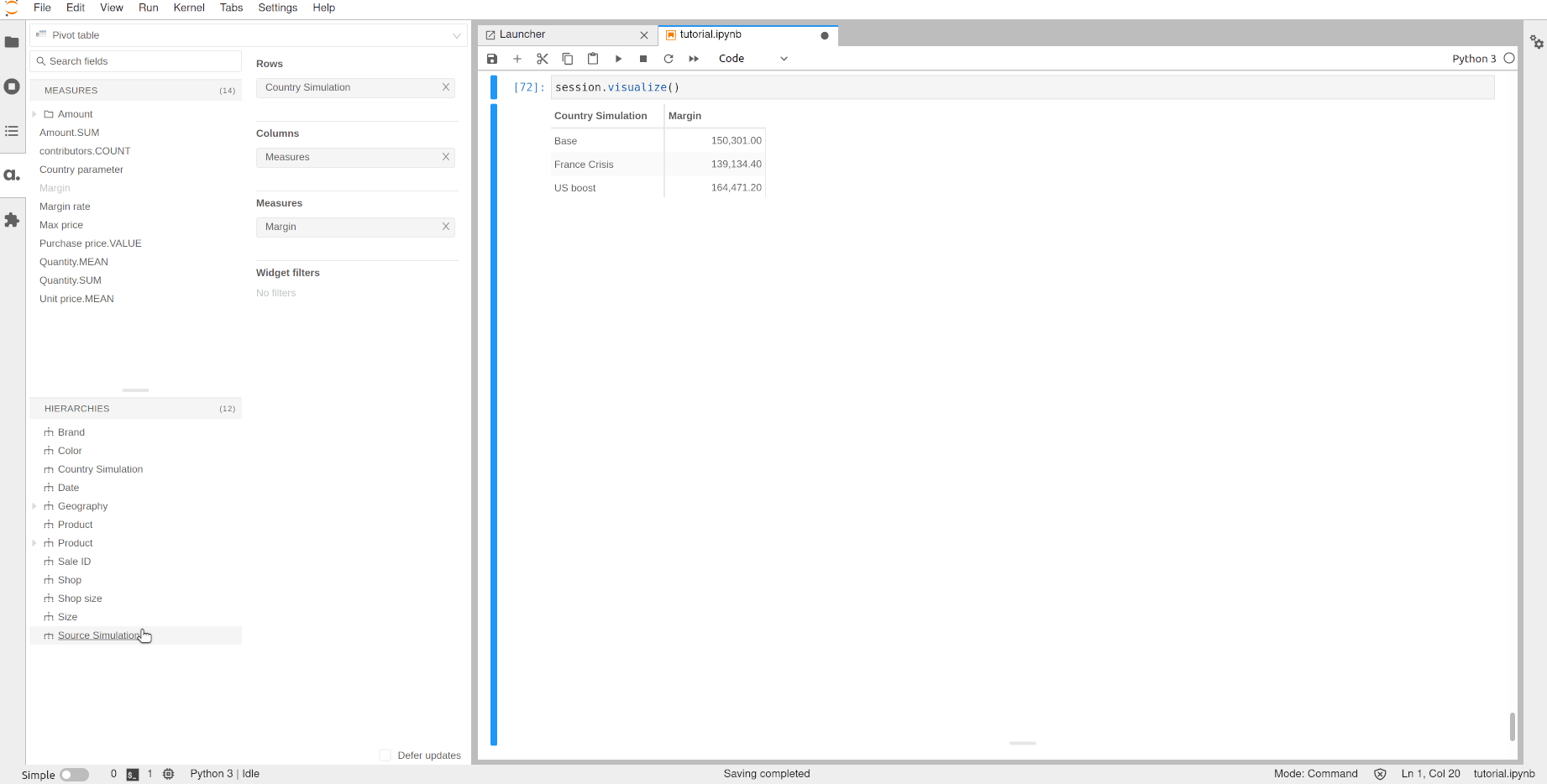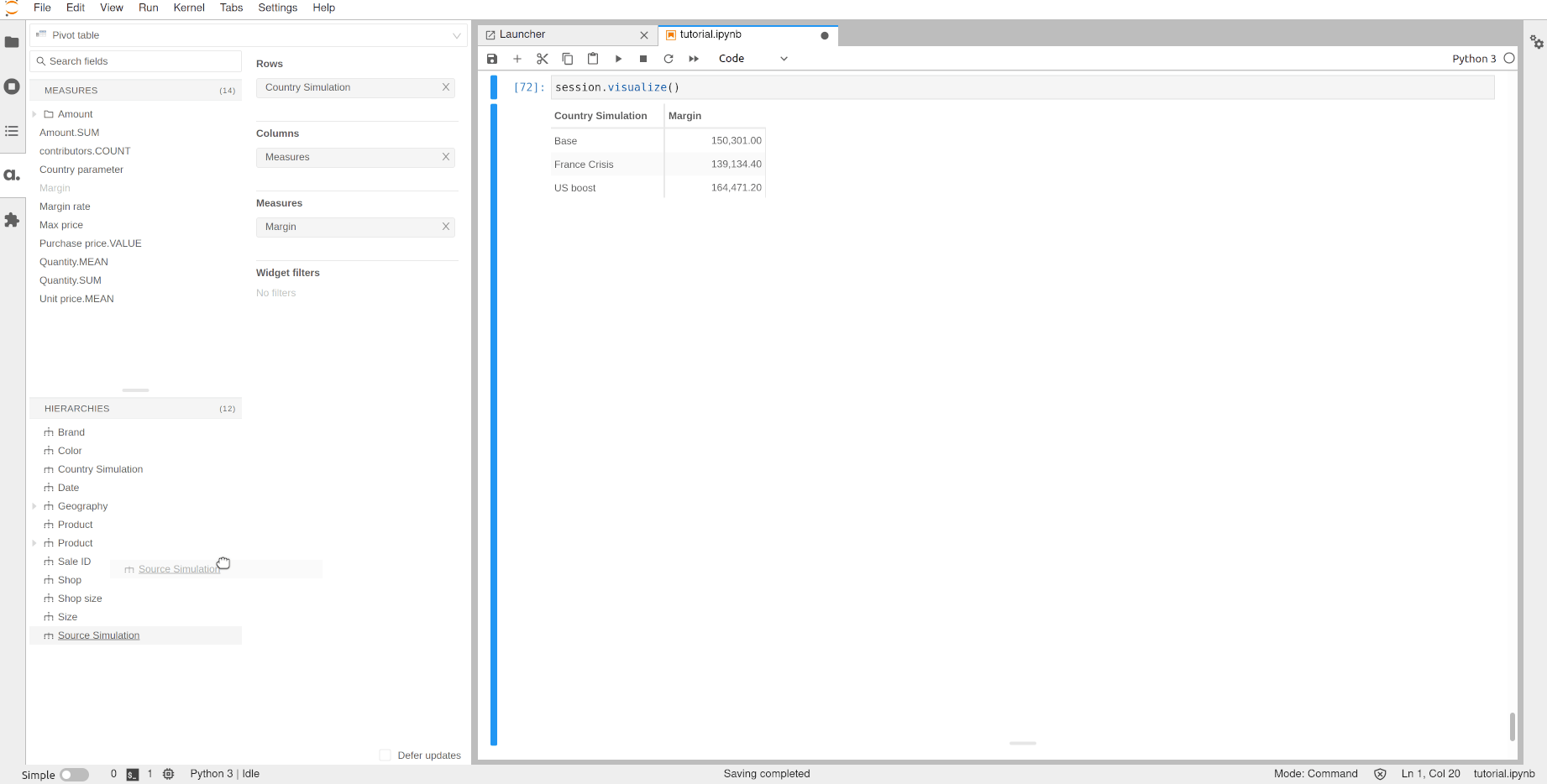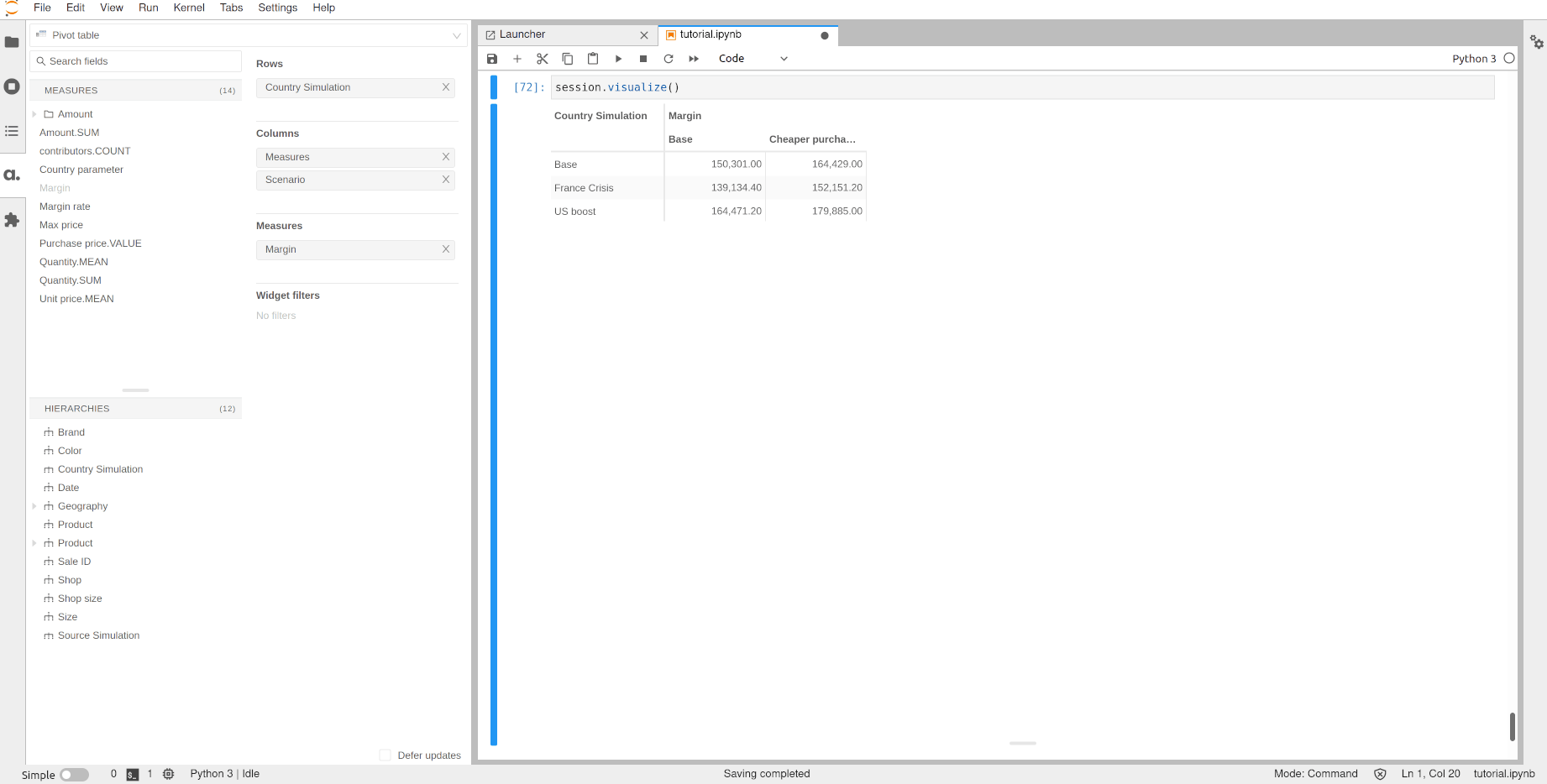
[72]:
session.visualize()
Open the notebook in JupyterLab with the atoti extension enabled to build this widget.
Going further#
You’ve learned all the basics to build a project with atoti, from the concept of multidimensional analysis to powerful simulations.
We now encourage you to try the library with your own data. You can also start to learn more advanced features such as session configuration, custom endpoints, querying, and arrays.